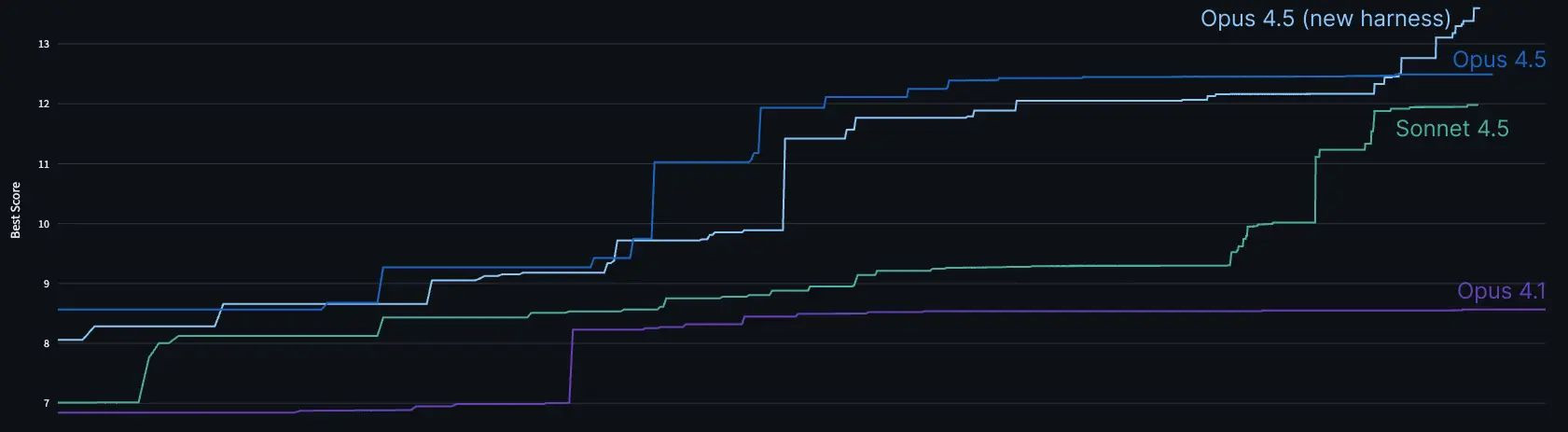
Anthropic omejuje uporabo Clauda v najbolj zaželenih terminih

Slo-Tech - Anthropic je ta teden uporabnikom svojega programerskega modela Claude nekoliko omejil njegovo uporabo. Kvote za uporabo (žetoni) se ponastavijo vsakih pet ur, doslej pa se je njihova uporaba ves čas obračunavala enako. Odslej bo uporaba med najbolj zaželenimi termini strožje vrednotena. Najbolj zaželeni termini so od 14. do 20. ure po srednjeevropskem času (oziroma od 5. do 11. ure v Kaliforniji).
Thariq Shihipar iz Anthropica je sporočil, da bo omejitev občutilo približno sedem odstotkov uporabnikov. Omejitev bo veljala v vseh paketih, tako v brezplačnem kot tudi plačljivih (Pro in Max). Tedenske kvote bodo ostale enake, le popoldne (v Evropi) bo možno postoriti manj. Ko uporabnik porabi svojo kvoto, mora uporabljati šibkejši in slabši model od ponastavitve čez pet ur.
Spomnimo, da je sredi meseca Anthropic vsem uporabnikom podvojil kvote za dva tedna. Ta obdobje se je sedaj izteklo, odslej pa bo treba nekoliko bolj taktično načrtovati, kdaj uporabljati Claude.
Thariq Shihipar iz Anthropica je sporočil, da bo omejitev občutilo približno sedem odstotkov uporabnikov. Omejitev bo veljala v vseh paketih, tako v brezplačnem kot tudi plačljivih (Pro in Max). Tedenske kvote bodo ostale enake, le popoldne (v Evropi) bo možno postoriti manj. Ko uporabnik porabi svojo kvoto, mora uporabljati šibkejši in slabši model od ponastavitve čez pet ur.
Spomnimo, da je sredi meseca Anthropic vsem uporabnikom podvojil kvote za dva tedna. Ta obdobje se je sedaj izteklo, odslej pa bo treba nekoliko bolj taktično načrtovati, kdaj uporabljati Claude.