OpenAI izdal odprta modela
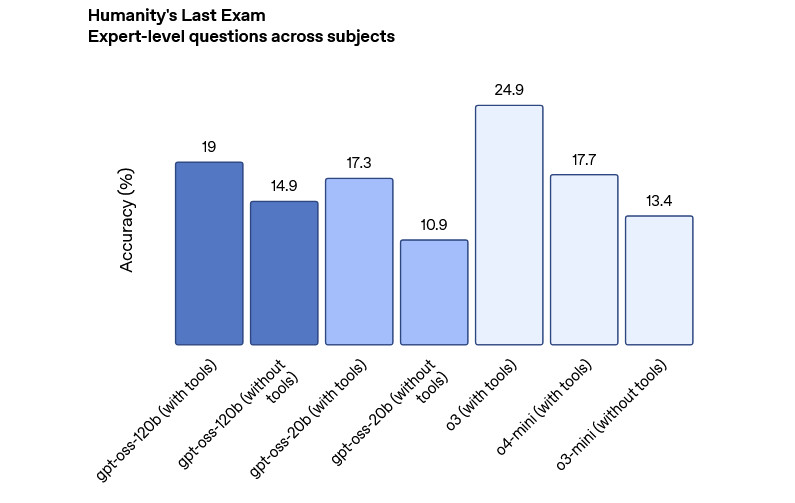
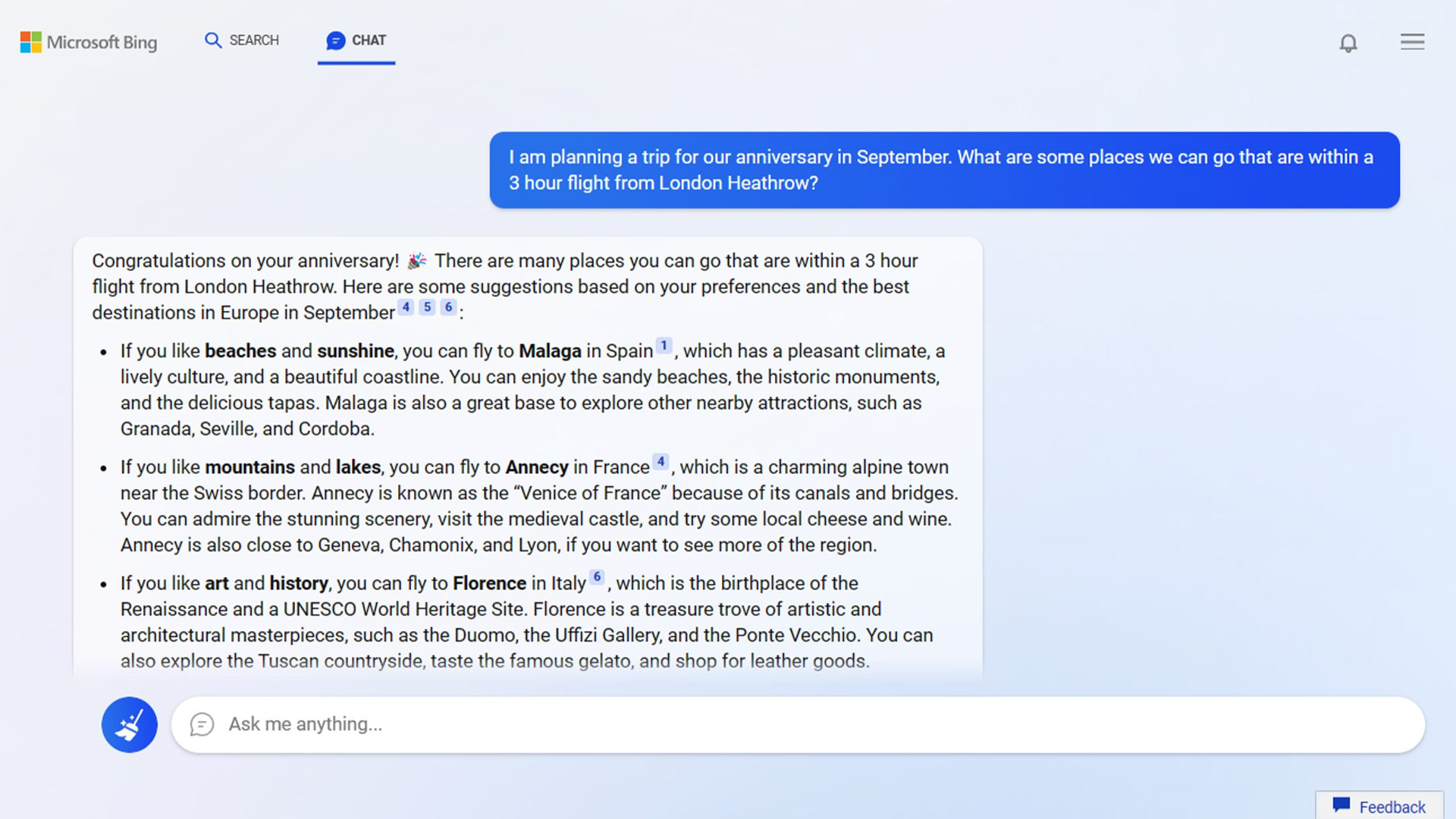
Slo-Tech - Po dolgem času, vse od že prazgodovinskega GPT-2, je OpenAI spet izdal velika jezikovna modela, ki imata javno dostopno drobovje. Modela gpt-oss-120B in gpt-oss-20B lahko prenesemo in poganjamo tudi na malce zmogljivejšem osebnem računalniku. Večji model zahteva grafično kartico z 80 GB pomnilnika, šibkejši pa 16 GB pomnilnika. To pa so že povsem dosegljive specifikacije.
Modela lahko poganjamo lokalno, lahko pa ju tudi prilagajamo in predelujemo. Izid so napovedali že minuli mesec, a je Sam Altman v zadnjem hipu zahteval dodatna varnostna preverjanja. To je pri odprtih modelih izjemno pomembno, saj jih po splavitvi ni možno ugasniti ali odpoklicati. Ko sta modela v svetu, bosta tam tudi ostala, dobila pa bosta še vse predelave, ki se jih bodo uporabniki lotili.
Modela sta izdana pod licenco Apache 2.0, torej ju je možno integrirati v Hugging Face, Ollamo, llamaa.cpp in vLLM.
Modela lahko poganjamo lokalno, lahko pa ju tudi prilagajamo in predelujemo. Izid so napovedali že minuli mesec, a je Sam Altman v zadnjem hipu zahteval dodatna varnostna preverjanja. To je pri odprtih modelih izjemno pomembno, saj jih po splavitvi ni možno ugasniti ali odpoklicati. Ko sta modela v svetu, bosta tam tudi ostala, dobila pa bosta še vse predelave, ki se jih bodo uporabniki lotili.
Modela sta izdana pod licenco Apache 2.0, torej ju je možno integrirati v Hugging Face, Ollamo, llamaa.cpp in vLLM.