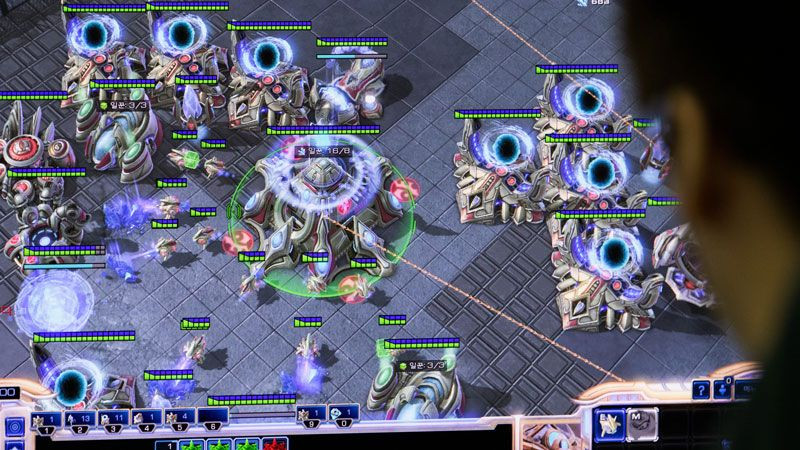
Raziskovanje strojnega učenja za svoje poligone uporablja vse zahtevnejše igre. Šahu, kjer je bila dovolj surova moč, je sledil Go, kjer je moral računalnik že razviti neko mero intuicije in strategije. Naslednja stopnja so igre z nepopolnimi informacijami in kompleksnejšimi razmerji med igralnimi enotami - kot je na primer Starcraft 2, ki so ga za izziv vzeli v Googlovem laboratoriju DeepMind. Januarja smo poročali o verziji agentov, ki so premagali profesionalna igralca TLOja in MaNo; toda dogodek je nosil važne opombe. AI je znala gledati po vsem ozemlju naenkrat, obenem pa je obvladala le Protosse in nekaj kart. Manj kot leto dni je trajalo, da je z opisane stopnje prešla na polnopravno sodelovanje na online strežnikih in se prebila v zgornji poldrugi promil (človeških) igralcev.
Pot do tja razkriva zanimive podrobnosti o napredku trenutno najbolj razširjenih načinov strojnega učenja. DeepMind, podobno kot OpenAI, krčevito prisega na globoke konvolucijske nevronske mreže v kombinaciji s posnemanjem in nadzorovanim ter utrjevanim učenjem. Pristop ima v najosnovnejši obliki velike hibe, ko naleti na kompleksne sisteme z neenakimi objekti, kot je na primer igra kamen-škarje-papir. Ko strojni agenti igrajo sami s seboj v takšnem režimu, so namreč nagnjeni k preveliki specializaciji in pozabljanju preteklih strategij, zaradi česar jih je zelo enostavno nadigrati s spremembo pristopa. V DeepMindu so se temu zoperstavili s treningom v virtualnih ligah, kjer so bili strojni agenti nenehno soočeni z množico rahlo različnih si nasprotnikov - od katerih so bili nekateri (tako imenovani exploiters) načrtno oblikovani za izkoriščanje njihovih lukenj v igranju. Tako so bile strojne pameti prisiljene ohraniti širok izbor sposobnosti.
Preden so takšne sorte AlphaStarja spustili na internet, so ga tudi dodobra omejili, da je bil po surovih zmogljivostih čim bližje človeku. Zgornja meja je bila 22 ukazov v intervalu petih sekund, računalnik pa je moral obenem tudi sam premikati zaslon, česar januarja še ni počel. Julija so tako igralci na evropskih strežnikih ugledali opcijo za igranje z umetno inteligenco. Ta je igrala anonimno, a so jo med eksperimentom nekajkrat vseeno zasačili, zato so morali v laboratoriju večkrat menjati uporabniška imena. Zadnja inačica se je nato na evropskem strežniku vendarle z vsemi tremi rasami prebila na najvišjo stopnjo - velemojstra (grandmaster), v zgornjega 0,15 procenta. Človeški igralci pravijo, da jo je bilo zgolj skozi igro zelo težko identificirati.
Raziskovalci so podrobne rezultate in delovanje agentov objavili v reviji Nature. (V uvodnem članku na DeepMindovem blogu stoji povezava na odprto verzijo ter posnetke.) Pravijo, da je s tem izziv zanje končan, kar pa je že sprožilo več pomislekov. Kot prvo, najboljšega človeškega igralca - Serrala - AlphaStar ob srečanjih še vedno ni uspel premagati. In kot drugo je pomenljivo, da so v laboratoriju največ truda usmerili v prilagajanje načinov učenja, medtem ko same arhitekture nevronskih mrež niso bistveno spreminjali, čeprav kitajske raziskave vse bolj kažejo, da se v kombiniranju konvolucijskih z drugimi oblikami skriva še ogromno rezerve. Tako smo v glavnem dobili novo poglobljeno študijo interkacije med podobnimi agenti, ki kažejo, kako okolica z izzivi nenehno izboljšuje naše sposobnosti.