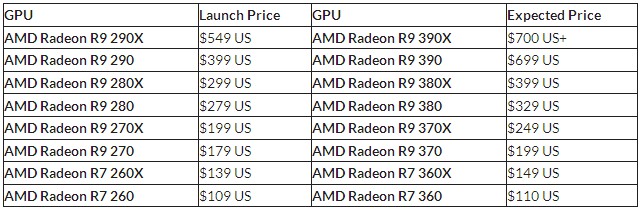
Slo-Tech - Sprva smo pričakovali, da bo AMD nove grafične kartice uradno predstavil na CeBIT-u, a jih bomo očitno dočakali šele na junijskem Computexu. Vseeno pa so v Hannovru pokazali, kaj bo prinesla prihodnost, ki sliši na Radeon R9 3xx. Novincev bo pravljičnih sedem, zajeli pa bodo vse segmente od najcenejšega do zelo dragega. Na enem koncu najdemo R7 360, na drugem koncu R9 390X, vmes pa še 360X, 370, 380, 380X in 390.
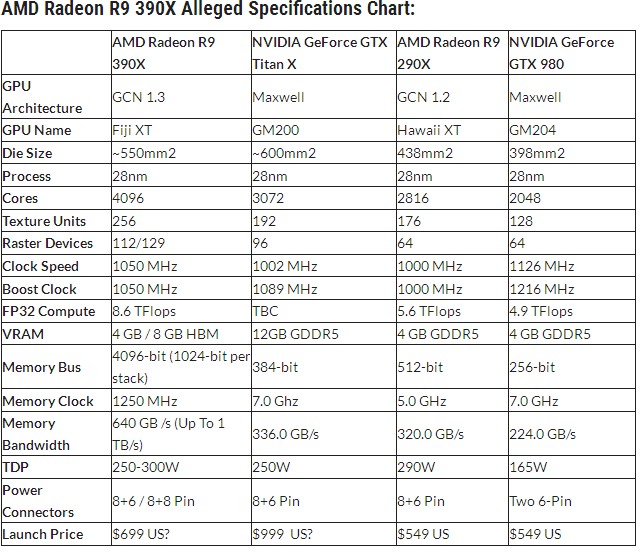
Poglejmo si najdražji model, ki bo po trenutni podatkih stal prek 700 dolarjev. R9 390X in nekoliko cenejši R9 390 bosta edina modela, ki bosta imela hiter pomnilnik (HBM), zaradi česar bosta občutno dražja od preostalih, po hitrosti pa bosta med R9 290X in dvojno kombinacijo R9 295X2. Vsak zase seveda, ne v kombinaciji. Najmočnejši R9 390x naj bi bil okrog 60 odstotkov hitrejši od R9 290X, trdijo v AMD-ju, imel pa bo 4 ali 8 GB pomnilnika HBM. Čip, izdelan v 28-nm tehnologiji na jedru Fiji XT, bo imel 4096 jeder, 256 teksturnih enot in frekvenco 1050 MHz, skupno torej 8,6 teraflops. Število ROP še ni znano, bo pa med 112-128. To bo prvi AMD-jev čip, ki bo omogočal gladko igranje iger ter navidezno resničnost v ločljivosti 4K pri 60 fps; doslej smo za to potrebovali dve kartici, kar pa je pomenilo do 300 W porabe.
Nekoliko nižje najdemo 380 in 380X, ki bosta stala 330 oziroma 400 dolarjev in bosta nasledila R9 290. Še stopnico niže se nahaja R9 370 za 200 dolarjev, ki bo nekje vmes med R9 270X in R9 285. Za 150 dolarjev bomo dobili R7 360X, ki bo nasledil R7 265, za 110 dolarjev pa R7 360 namesto R7 250X oziroma 260X.
AMD se je znašel v precej zapletenem položaju. Po eni strani mora hitro izdati nove čipe, da mu Nvidia ne pobegne preveč in odžre prevelik tržni delež, po drugi strani pa bodo novi čipi učinkoviti pristrigli peruti prodaji (beri: kanibalizirali) trenutne generacije R9 2xx, kar spet ni pametno. In tako na CeBIT-u ne bo nič, aprila bržčas ne bo nič, junija na Computexu pa bomo videli, kaj bo AMD postoril.
v bistvu niti ne rabimo za 1080p nič kaj novega (boljše bi bilo seveda, če bi bilo!?), ciljajo na tiste, ki bodo itak že dali veliko za qhd monitor in s 390x ne bodo gledali na nič drugega kot na performance
370x bo zanimiva zadeva do 300 EUR in seveda 960ti, to bo še za videti katero
vse višje je cenovno zelo vprašljivo, me prav zanima na kaj ciljajo z 380/x
kako pa bo s kanibalizacijo 290/x? ne verjamem, da bodo 290 za 200 EUR prodjali
hja govorice so na eni strani da so vse od 380x navzdol rebrandi starih jeder, na drugi strani, pa da naj bi se v AMDju pred kratkim premislili in da so to nova jedra... zdej pa kateri govorici verjeti...
Kaj je point da dajo nove kartice vn pa prakticno nic nove tehnologije in ppreformenc in price zelo podobna prejsnim modelom.. bolj smiseklno bi bilo nadaljevati "staro " produkcijo
samo optimizacija obstoječe arhitekture (texture compression recimo).
Dejte si že utepst v glavo: texture compression ni enako framebuffer compression. Texture compression je definiran s strani D3D/OpenGL. Framebuffer compression je nekaj kar delajo IHV-ji transparentno od API-ja in nima čisto nikakršne veze s teksturami. Framebuffer compression je tudi nekaj kar GPU-ji delajo že od Radeon 7000 in GeForce 4 naprej (to je bil eden od razlogov, zakaj je Matrox Parhelia precej spektakularno pogorela). Kar se dogaja je, da IHV-ji vsake toliko ta "kompresiran" blok povečajo, ker se resulucije in AA dvigajo.
Pričakoval bi, da če je 390X zamenjava za 290X, bi morala nova kartica 390X imeti isto oz podobno ceno kot sedanja 290X in ponujati višjo zmogljivost. Če pa je kartica 150 $+ dražja, zame to ni isti rang in ne morem temu reči zamenjava 290X -> 390X. Če znajo kaj res dobro, znajo cene dvigovat. Škoda, da niso kr na okroglo cifro zaokrožili 1000$ pa bi blo.
Lp
:4770K@4.5GHz @ BeQuiet!Dark Rock Pro2; MSI Z87 GD65 Gaming; 16GB RAM:
::GTX 1060 6GB; SSD Samsung 840 EVO 250GB; SEAGATE 3TB+3TB+1TB; LG 27"IPS::
:::: XFX 850W Black Edition; X-Fi Titanium; Fractal Design ARC R2 ::::
samo optimizacija obstoječe arhitekture (texture compression recimo).
Dejte si že utepst v glavo: texture compression ni enako framebuffer compression. Texture compression je definiran s strani D3D/OpenGL. Framebuffer compression je nekaj kar delajo IHV-ji transparentno od API-ja in nima čisto nikakršne veze s teksturami. Framebuffer compression je tudi nekaj kar GPU-ji delajo že od Radeon 7000 in GeForce 4 naprej (to je bil eden od razlogov, zakaj je Matrox Parhelia precej spektakularno pogorela). Kar se dogaja je, da IHV-ji vsake toliko ta "kompresiran" blok povečajo, ker se resulucije in AA dvigajo.
Ali lahko malo več poveš kaj se dogaja pri tej kompresiji bufferja. Verjetno ta kompresija ni brez izgub? Če se frame razdeli na bloke npr. 16x16 pikslov in se kompresira posamezne bloke. Ali je zadaj kaka enostavna detekcija kateri blok se bo kompresiral? Ali še vedno uporablajajo kompresijo z manjšanjem števila bitov za zapis posameznega piksla ali je postala ta kompresija kaj bolj zahtevna? Ali so potem bloki po kompresiji fiksne dolžine ali dinamične? Namreč, če so dinamične dolžine, potem je verjetno potreben še nek dodaten predpomnilnik, ki pove, kje se v pomnilniku nahajajo ti skompresirani bloki. Kako je s tem?
tako ceno bi pričakovali z novo generacijo na 20nm ali manjšem procesu, ne pa to, sicer pa se itak gre za grafe za tiste, ki vejo zakaj toliko več za plačat
kupiš 390x ali 980ti, pa imaš čez 2 leti grafe za 3x manj denarja na istem nivoju v novem srednjem razredu
Zakaj popravljena? Saj slika je popolnoma pravilna.
Zako, ker tisti, ki je dal kak predmet prof. Mraza čez, potem ve, da se izhodišče grafa začne pri 0. Razen, če delaš v markentingu potem se lahko začne pri 0.98 in konča pri 1.02. Sploh, če delaš kako primerjavo med dvema produktoma. V resnici se niti ne rabi dati nobenega posebnega predmeta čez, da je človeku jasno, da se tega tako ne dela, kot je prikazano v zgornjem originalnemu grafu.
S tretjimmi besedami: bedak je tisti, ki je tak graf narisal, če večji pa tisti, ki ga je požegnal Kot pri ostalih stvareh, obstajajo tudi pri risanju grafov neka pravila, ki se jih normalen človek drži, bedaki so pa pač bedaki. Obstajajo pa dve vrsti bedakov: ena je nerazgledana vrsta, katera ta pravila ne poznajo, druga pa je zavajujoča vrsta. Še dobro, da so zraven dodali skalo, dugače bi človek mislil, da je nov produkt vsaj 3x boljši od starega.
Ali lahko malo več poveš kaj se dogaja pri tej kompresiji bufferja. Verjetno ta kompresija ni brez izgub? Če se frame razdeli na bloke npr. 16x16 pikslov in se kompresira posamezne bloke. Ali je zadaj kaka enostavna detekcija kateri blok se bo kompresiral? Ali še vedno uporablajajo kompresijo z manjšanjem števila bitov za zapis posameznega piksla ali je postala ta kompresija kaj bolj zahtevna? Ali so potem bloki po kompresiji fiksne dolžine ali dinamične? Namreč, če so dinamične dolžine, potem je verjetno potreben še nek dodaten predpomnilnik, ki pove, kje se v pomnilniku nahajajo ti skompresirani bloki. Kako je s tem?
Ta kompresija je brez izgub in je vedno bila in vedno bo. Nihče ne garantira, da v bufferju niso dejansko npr. kakšni geometrijski podatki, kjer bi napaka ne bo spremenila za malenkost odtenka ampak teleportirala particle 30m stran (ali pa še bolje eno oglišče trikotnika 20m stran). Iz istega razloga se tudi ni nikoli uporabljalo kakšnega manjšanja bitne globine bufferja (eksplicitno nočem omenit slike). Ti bloki so tudi vedno fiksne dolžine (plus da dobimo zraven zastavico za "ali je blok kompresiran"). Ne morejo biti dinamične že iz razlogov, ki si jih sam omenil. Dodatno pa bi kakršna koli dinamika pomenila da vsak ROP blok v GPU ne more v vsakem trenutku vedet kam mora pisat in se cela paralelna paradigma GPU-ja podre. Iz tega razloga ta pristop tudi ne prihrani prostora. Prihrani samo bandwidth, ker bo GPU lahko namesto za cel blok bajtov zapisal precej manj bajtov.
Če si predstavljaš 4x4 blok pixlov, ki so povsem znotraj trikotnika. GPU bo vzel teh 16 pixlov s katerimi trenutno dela in preveril koliko se barve razlikujejo. Če mu uspe stlačit teh 16 pixlov v nekaj ključnih barv in odmikov od tega (brez izgub!), potem je lahko blok (trenutno) kompresiran. Zapiše se recimo 4 byte za prvi ključ, 4 byte za drugi ključ in potem recimo 4 bite za vsak pixel torej še 8 bytov in skupaj 16 bytov. Namesto 64 bytov za nekompresiran primer. Isto se zgodi za zbuffer (tukaj že nimamo več opravka z barvami, ampak z "globino slike", kar vpliva na geometrijo). Če si predstavljaš da imaš še 4x MSAA potem se tisti 4x4 blok zmanjša na 2x2 pixla (4 barvni sampli za vsak pixel). To je še posebej idealno za kompresijo, ker razen, če shader eksplicitno ne spreminja posameznih vzorcev, so vsi 4-je sampli povsem identični. Torej imaš dejansko max 4 različne barve, dve bosta ključni, dve pa "nekje vmes". Skratka super prijazno za kompresijo. GPU mora bit seveda pozoren tudi na primer, ko nek trikotnik ne spremeni vrednosti celega 4x4 bloka, ampak recimo zgolj samo 1 pixel. V tem primeru mora GPU prebrat blok nazaj v GPU in ponoviti zgoraj opisano vajo.
Skratka cel kup različnih primerov. Zgodovinsko se je najprej kompresiralo z-buffer. Potem se je začelo kompresirati tudi back buffer. Potem se je povečalo blok (in vpeljalo dodatne primere. da je bilo možno kompresirat več kombinacij). In sedaj se je ponovno povečalo blok in razširilo nabor pokritih kombinacij. Maxwell je torej dejansko 4. iteracija tega.
Zakaj popravljena? Saj slika je popolnoma pravilna.
Zako, ker tisti, ki je dal kak predmet prof. Mraza čez, potem ve, da se izhodišče grafa začne pri 0. Razen, če delaš v markentingu potem se lahko začne pri 0.98 in konča pri 1.02. Sploh, če delaš kako primerjavo med dvema produktoma. V resnici se niti ne rabi dati nobenega posebnega predmeta čez, da je človeku jasno, da se tega tako ne dela, kot je prikazano v zgornjem originalnemu grafu.
Hrabri mišek (od 2015 nova serija!) -> http://tinyurl.com/na7r54l
18. november 2011 - Umrl je Mark Hall, "oče" Hrabrega miška
RTVSLO: http://tinyurl.com/74r9n7j
Zakaj popravljena? Saj slika je popolnoma pravilna.
Zako, ker tisti, ki je dal kak predmet prof. Mraza čez, potem ve, da se izhodišče grafa začne pri 0. Razen, če delaš v markentingu potem se lahko začne pri 0.98 in konča pri 1.02. Sploh, če delaš kako primerjavo med dvema produktoma. V resnici se niti ne rabi dati nobenega posebnega predmeta čez, da je človeku jasno, da se tega tako ne dela, kot je prikazano v zgornjem originalnemu grafu.
... pol pa vzamejo logaritemsko skalo.
Saj ne primerjamo današnje grafične kartice s kartico 30 let nazaj.
Zakaj popravljena? Saj slika je popolnoma pravilna.
Zako, ker tisti, ki je dal kak predmet prof. Mraza čez, potem ve, da se izhodišče grafa začne pri 0. Razen, če delaš v markentingu potem se lahko začne pri 0.98 in konča pri 1.02. Sploh, če delaš kako primerjavo med dvema produktoma. V resnici se niti ne rabi dati nobenega posebnega predmeta čez, da je človeku jasno, da se tega tako ne dela, kot je prikazano v zgornjem originalnemu grafu.
a tistega mraza, ki na predavanjih bluzi o lunarnih nepristankih in stanleyu kubricku in drugih neumnostih?
tale graf je sicer res zavajajoč in čisto marketniški, ni pa prav nikjer napisano da mora biti ali pa naj bi bilo tako da se graf začne v (0, 0)
Hvala, meni je v glavnem pomembna samo poraba in da se da dobit single-slot varianto kartice
Hrabri mišek (od 2015 nova serija!) -> http://tinyurl.com/na7r54l
18. november 2011 - Umrl je Mark Hall, "oče" Hrabrega miška
RTVSLO: http://tinyurl.com/74r9n7j
Tu se mi pa pojavi še nekaj vprašanj glede shranjevanja oz hranjenja blokov v pomnilniku. Če sem prav razbral sta širina in višina oz. število pikslov v bloku v naprej določeni glede na arhitekturo. Verjetno potem bloki niso v pomnilniku shranjeni v zaporednem vrstem redu, saj bi drugače, čeprav se nekatere bloke kompresira, še vedno imeli bloke v pomnilniku na istem mestu, samo krajši bi bili, imeli bi notranjo fragmentacijo, s tem pa ne bi nič prihranili na prostoru. Če bi hoteli zgoštevati posamezne kompresirane bloke oz. premetavati kompresirane in nekompresirane bloke v prostror, ki bi ga prihranili z kompresijo, potem se tu verjetno pojavi precej težav in vprašanj, če se v resnici dela tako. Oz vsaj obstajati bi moral še nek dodaten ((set) asociativen)pomnilnik, ker si omenil zastavice, kjer bi se shranjevali kontrolni podatki glede posameznih blokov. Ampak glede na to, kompresija ni omejena samo na barvni buffer, je verjetno kaka druga rešitev, ki omogoča hitro in kompaktno shranjevanje blokov v pomnilniku. Seveda me pa zanima ali je to narejeno strojno in transparentno ali za to (shranjevanje in premetavanje blokov) skrbi gonilnik?
Zakaj popravljena? Saj slika je popolnoma pravilna.
Zako, ker tisti, ki je dal kak predmet prof. Mraza čez, potem ve, da se izhodišče grafa začne pri 0. Razen, če delaš v markentingu potem se lahko začne pri 0.98 in konča pri 1.02. Sploh, če delaš kako primerjavo med dvema produktoma. V resnici se niti ne rabi dati nobenega posebnega predmeta čez, da je človeku jasno, da se tega tako ne dela, kot je prikazano v zgornjem originalnemu grafu.
a tistega mraza, ki na predavanjih bluzi o lunarnih nepristankih in stanleyu kubricku in drugih neumnostih?
tale graf je sicer res zavajajoč in čisto marketniški, ni pa prav nikjer napisano da mora biti ali pa naj bi bilo tako da se graf začne v (0, 0)
Če se mraza samo po nekaterih takih izjavah spomniš, jaz se sicer kakih takih njegovih izjav ne spomnim, potem je vprašanje, če si sploh od njegovih predavanja kaj odnesel.
Če boš iskal po kakih zakonih, kak mora biti graf, potem tega ne boš našel. Načeloma ni potrebno, da se graf začne v 0,0. Velja pa za zgornji graf. Pa tudi v večini primerov za prezentacijo množici je tako. Je precej gradiva na spletu zakaj, kako in kako se ne dela grafe. Upam, da ni treba posebej napisati zakaj je temu tako. Ni prav nobenega posebnega razumnega razloga, da inženirji ne bi uporabljali zdravo pamet pri risanju grafov. Če že v marketingu ne znajo prikazovati primerjav z grafi, je dobro, da vsaj nekdo kak graf popravi in prikaže, kako se pravilno naredi graf.
Moj point je bil samo, kako se trudijo prikakazati 3x večji performance, kot pa je dejansko. Če ne povečaš slike, se sploh neve od kod se začne, kar je dovolj za 99% userjev, ki samo mimobežno preletijo take in onakve grafeke.
Če se mraza samo po nekaterih takih izjavah spomniš, jaz se sicer kakih takih njegovih izjav ne spomnim, potem je vprašanje, če si sploh od njegovih predavanja kaj odnesel.
njegova predavanja so bila bolj meh, govoril je o prihodnosti računalništva na splošno ampak sem bil malo razočaran ker ni zgledal zelo na tekočem s področjem, kar je bilo na predavanjih bi si pa lahko v 4x manjšem času prebral na wikipediji in od tega več odnesel. predavanja na 2. stopnji fakultete s strani ljudi z doktorskim nazivom so namenjena temu da se podaja snov ki ni glih v "summary" sekciji članka na wikipediji.
predmet sicer eden najlažjih na faksu, da se ga spomnim po tem da je 10 minut skupaj razlagal o tem kako je cubrick v studiu snemal apollo 11 pa mi ne more noben očitat. profesor gor ali dol, za moje pojme oseba s takimi nazori ni preveč razgledana.
Tu se mi pa pojavi še nekaj vprašanj glede shranjevanja oz hranjenja blokov v pomnilniku. Če sem prav razbral sta širina in višina oz. število pikslov v bloku v naprej določeni glede na arhitekturo. Verjetno potem bloki niso v pomnilniku shranjeni v zaporednem vrstem redu, saj bi drugače, čeprav se nekatere bloke kompresira, še vedno imeli bloke v pomnilniku na istem mestu, samo krajši bi bili, imeli bi notranjo fragmentacijo, s tem pa ne bi nič prihranili na prostoru. Če bi hoteli zgoštevati posamezne kompresirane bloke oz. premetavati kompresirane in nekompresirane bloke v prostror, ki bi ga prihranili z kompresijo, potem se tu verjetno pojavi precej težav in vprašanj, če se v resnici dela tako. Oz vsaj obstajati bi moral še nek dodaten ((set) asociativen)pomnilnik, ker si omenil zastavice, kjer bi se shranjevali kontrolni podatki glede posameznih blokov.
Če se omejimo na NV (čeprav točno tudi za Maxwella ne vem koliko pixlov je ta blok dejansko velik) potem pride ta blok pixlov vedno iz enega ROP clustra in je torej na Maxwellu vedno na dveh pomnilniških čipih, ki sta privezana na ta ROP cluster. Sosednji blok bo šel čez drug ROP cluster in bo pristal na drugih dveh pomnilniških čipih. Kot sem že omenil, kompresirani bloki še vedno zasedejo celotno velikost pomnilnika (+ekstra, da čip ve kateri so kompresirani). Iz x,y pozicije pixla v bufferju lahko točno veš kater ROP bo zadevo zrenderiral in v katerem pomnilniškem čipu bo pristala. Ne moreš si privoščit, da bo kompresiran blok zasedel manj prostora v ramu. Če ga boš moral odkompresirat, ker se bo v isti blok izrisalo še nekaj pixlov nekega drugega trikotnika... Cel buffer je (generally) linearen, ni razbit na neke distinktne bloke, kjer boš do vsakega od stotih prišel z enim od 100 pointerjev. Če si predstavljaš, da se slika razbije v 8x4 pixlov velike bloke, potem bodo pixli za prvi blok levo zgoraj vedno padli iz prvega ROP clustra na prva dva pomnilniška čipa. Desni sosednji blok pride iz drugega ROP clustra na druga dva pomnilniška čipa. Spodnji sosedni blok pride iz tretjega ROP clustra. Desni spodnji sosed pride iz četrtega ROP clustra. Tretji blok v zgornji vrsti spet pade iz prvega ROP clustra itd.
Ampak glede na to, kompresija ni omejena samo na barvni buffer, je verjetno kaka druga rešitev, ki omogoča hitro in kompaktno shranjevanje blokov v pomnilniku. Seveda me pa zanima ali je to narejeno strojno in transparentno ali za to (shranjevanje in premetavanje blokov) skrbi gonilnik?
Kompaktno se kompresira samo teksture (S3TC/DXTC oziroma BCx po novem). To ne kompresirajo driverji ampak že igra priskrbi kompresirane podatke. In s te strani kompresija ni brez izgub. Glede frame buffer kompresije je zadeva speljana transparentno od API-ja (D3D/OpenGL). Driver pa seveda mora vedet ali je zadeva kompresirana ali ne. Danes se pogosto izrisuje v teksture. Ni nujno, da hardware za teksturiranje zna brat kompresirane podatke, ki so jih ROP-i zapisal v memory. Driver mora ta primer ujet in interno naredit konverzijo. Zato imajo tudi API-ji restrikcijo, da nek buffer ne sme bit hkrati input in output (tekstura in render target).
Recimo en dober primer kako to izgleda v praksi je tule. Če pogledaš Beyond3D test suite - Bandwidth grafe vidiš konkretno razliko, če je uporabljena tekstura enobarvna ali pa če je napolnjena s šumom, ki se ga ne da kompresirat.
Moj point je bil samo, kako se trudijo prikakazati 3x večji performance, kot pa je dejansko. Če ne povečaš slike, se sploh neve od kod se začne, kar je dovolj za 99% userjev, ki samo mimobežno preletijo take in onakve grafeke.
Zdej si pa predstavljej specifikacije gtx 970 ki jih strokovnjaki niso mogli pol leta razbrat pravilno.