Članki » Strokovni članki » Strežniki: Xeon vs. Opteron
Strežniki: Xeon vs. Opteron
- Jure Pecar ::
Danes so za vsakdanja opravila pisarniški računalniki že tako zmogljivi, da se na njihove zmogljivosti oziramo veliko manj kot na ceno in priloženo programsko opremo. Dobro vemo tudi, kaj pričakujemo od igračarskih PCjev in kako to izmerimo: toliko gigahercev, toliko FPSov v tej in tej igri, toliko in toliko megabajtov rama na grafični kartici in to je to. Kako pa se tega lotimo pri strežnikih? Pravzaprav se moramo vprašati, kaj sploh pričakujemo od strežnika.
Medtem ko od igračarskega PCja pričakujemo čim hitrejše izvajanje enega samega programa (glavna logika se izvaja kar iz procesorjevega predpomnilnika, teksture se naložijo na grafično kartico, ...), od strežnika ponavadi pričakujemo sposobnost poganjati čim več programov hkrati, pri čemer morajo biti vsi vsaj toliko odzivni, da jih uporabnik še lahko normalno uporablja. Ta zahteva postavlja pred snovalce strežniških sistemov popolnoma drugačne izzive kot nek igračarksi PC.
Glavni način, kako zagotoviti odzivnost več vzporedno izvajajočim se programom je, da ponudimo vsakemu svoje procesorsko jedro, na katerem se izvaja. Tako v svetu pc strežnikov najdemo dvo- in štiriprocesorske sisteme, v svetu UNIX strežnikov pa gre ta številka danes vse do 512 procesorjev v t.i. single-image sistemu, kjer en operacijski sistem deluje hkrati z vsemi procesorji (SGI Altix). Pa je tak sistem tudi 512-krat hitrejši od enoprocesorskega? Odgovor je sevda ne. Pa si poglejmo, kaj je temu vzrok.
Če se na enem procesorju izvaja en sam program in če je ta program relativno enostaven, se lahko v celoti izvaja iz procesorjevega predpomnilnika. Težavi sta dve: na strežnikih ponavadi teče veliko več programov kot ima strežnik procesorjev, poleg tega pa strežniki ponavadi izvajajo relativno enostavne operacije nad ogromnimi količinami podatkov, od katerih lahko le manjši del spravimo v sistemski pomnilnik, kaj šele v procesorjev predpomnilnik. Zato operacijski sistem sproti prilagaja urnik izvajanja posameznega programa na posameznem procesorju, vsakič pa, ko pride do zamenjave, mora procesor znova naložiti nov program iz sistemskega pomnilnika v svoj predpomnilnik, nato pa poiskati še vse aktulane kose podatkov za obdelavo. Iz česar sledi, da mora strežniški sistem imeti izredno dobro razvite t.i. I/O kanale, začenši s povezavo diskov in sistemskega pomnilnika, zunanjih naprav (mreža, ...) in sistemskega pomnilnika ter seveda sistemskega pomnilnika in procesorjev.
Deloma se ta problem v velikih sistemih rešuje s t.i. NUMA arhitekturo (Non-Unified Memory Arhitecture). Njena značilnost je, da je glavni pomnilnik ni več samo en in skupen vsem procesorjem, pač pa ima vsak procesor svoj lokalni pomnilnik, hardver pa poskrbi za to, da so vsi ti lokalni pomnilniki vidni kot en velik skupni pomnilnik. Seveda se mora razvrščevalnik sistemskih sredstev operacijskega sistema zavedati te arhitekture in posameznim procesorjem odrejati izvajanje le tistih programov, ki so trenutno v njihovem lokalnem pomnilniku ("CPU affinity"). Ker pa to ni vedno možno, mora biti med procesorji oz. njihovimi lokalnimi pomnilniki zmogljivo vodilo, ki zmore v čimkrajšem času prenesti velike količine podatkov.
Vodila, ki jih poznamo kot navdušeni "šraufalci" računalnikov, segajo od starejših ISA in EISA pa preko PCI (ter širšega PCI-X) in AGP do danes aktualnega PCI Express. Vendar so vsa ta vodila namenjena povezavi "zunanjih" naprav, kako pa so povezani procesorji in pomnilnik, pa nas proizvajalci kot končne uporabnike ne obremenjujejo, saj mora to skrbeti "le" inžinerje, ki načrtujejo sisteme. Intelovo vodilo med procesorji in north brgidgeom se recimo imenuje AGTL+ in o njem skorajda ne slišimo.
Xeon
Pa si oglejmo, kako danes izgleda tipična dvoprocesorska x86 arhitektura:
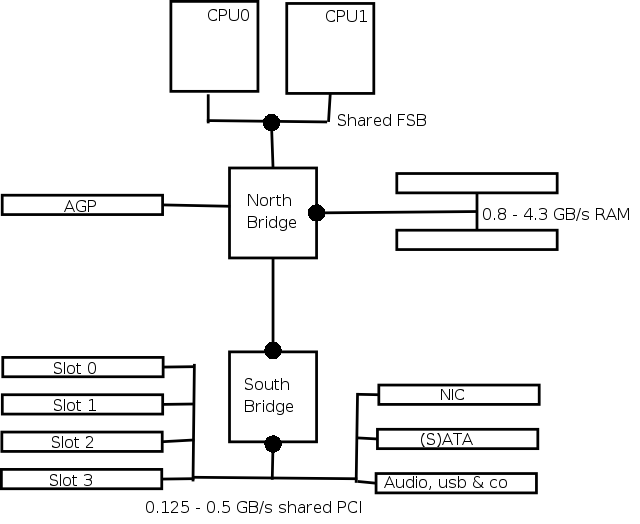
Na tej shemi lahko takoj prepoznamo precej ozkih grl: procesorja si delita vodilo do pomnilnika, relativno majhna je prepustnost vodila do RAMa, north bridge in south bridge sta povezana ponavadi kar s PCI vodilom, naprave, obešene na south bridge, si delijo isto PCI vodilo. Tako je danes zasnovanih večina pentium II, III in 4 ter athlon osnovnih plošč, na žalost pa take najdemo tudi med cenejšimi xeon strežniki.
Xeon (oz. Pentium 4) arhitektura je znana po tem, da zaradi svojega dolgega cevovoda potrebuje zelo hiter dostop do pomnilnika. Ta je problematičen že z enim samim procesorjem, če pa na isto vodilo obesimo dva (ali bog ne daj, štiri), je problem še toliko bolj očiten. Zato FSB namesto "Front Side Bus" vedno pogosteje predstavlja "Front Side Bottleneck".
Na današnjih ploščah vedno pogosteje srečamo tudi gigabitni ethernet, ki je obešen kar na navaden 32bit 33MHz PCI. Njegova največja teoretična prepustnost znaša 133MB/s, tako da če nam uspe na mreži doseči prenos 1Gb/s (128MB/s), nam na PCI vodilu ne preostane prostora za ničesar drugega. Razen tega deljeno vodilo pomeni, da v danem trenutku lahko s procesorjem komunicira natanko ena naprava.
Strežniški PCji se od navadnih razlikujejo le malo:
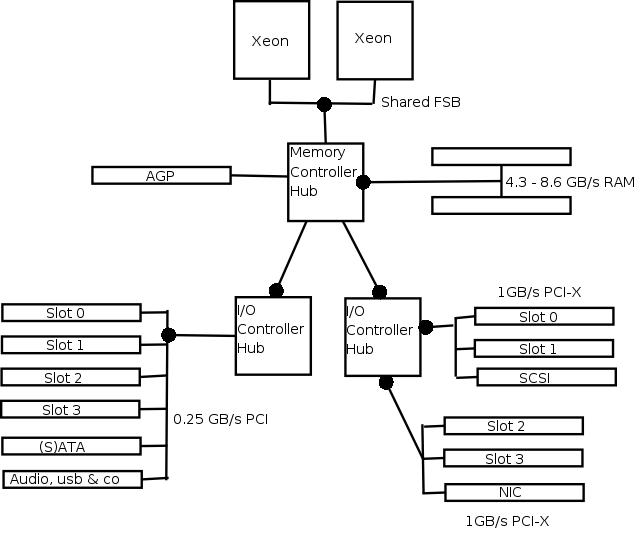
Vidimo pomembne razlike, kot to, da je Intel north bridge poimenoval Memory Controller Hub (MHC) in south bridge I/O Controller Hub (ICH) ter nekaj hitrejše pomnilink in PCI vodila, ki jih je sedaj lahko več. Gigabitni ethernet je prestavljen na širše vodilo PCI-X, kamor spada, pravtako pa na njem najdemo tudi SCSI kontroler, ki je podobno kot mreža na večini strežniških plošč že integriran.
Taka arihtektura še vedno pomeni, da je dvoprocesorski sistem le 60% hitrejši od enoprocesorskega, štiriprocesorski pa le 10% od dvoprocesorskega! Zato rečemo, da je skalabilnost PC arhitekture zelo slaba. Vendar še vedno hočemo več, kar zahteva spremembo arhitekture:
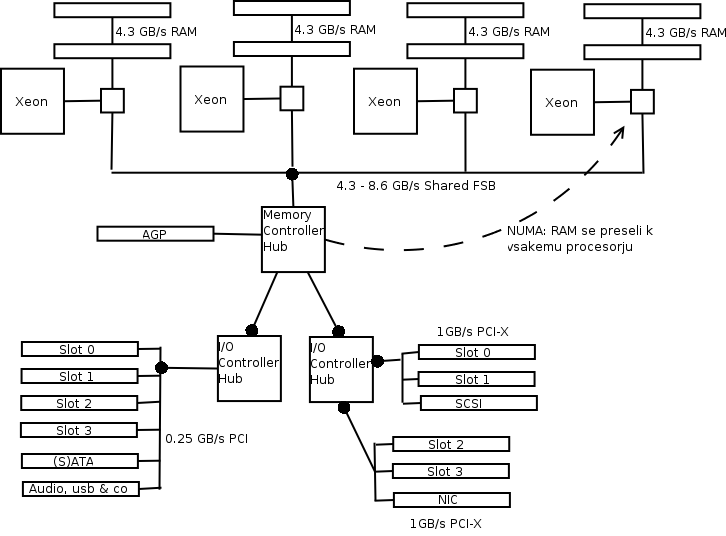
Na shemi lepo vidimo, kaj točno pomeni kratica NUMA. Vsak procesor ima svoj kos pomnilnika, s katerim komunicira s polno hitrostjo. Taka arhitektura je veliko bolj skalabilna, saj poznamo strežnike s 16 in celo 32 Xeon procesorji (Unisys ES7000). Vendar še vedno obstajajo težave: procesorji so povezani med seboj in z zunanjimi napravami še vedno preko relativno počasnega FSBja, taka arhitektura ni več standard(izira)na, kar pomeni precej večjo ceno tako za razvoj kot vzdrževanje.
Zato strežniški svet potrebuje standardno, "off the shelf" NUMA rešitev za relativno nizko ceno. Pa si poglejmo, kako to rešuje Opteron s HyperTransportom.
Opteron
Korenine HyperTransporta segajo nazaj v devetdeseta leta v takrat eno izmed najmočnejših podjetij, DEC, ki je razvilo procesorje Alpha. Po tem, ko so pri svojih EV4 in EV5 dizajnih preizkusili približno vse možne pristope k dizajnu chipseta, so z EV6 izdelkom ustvarili nekaj, kar še danes uporabljamo na vseh Athlon ploščah. Po seriji napačnih poslovnih potez so DEC razprodali, glavnina Alpha ekipe je ustanovila podjetje Alpha Processor inc, ki se je kasneje preimenovalo v API Networks in ga je prevzel AMD. Bogate izkušnje Alpha ljudi so koristno uporabili pri snovanju univerzalnega vodila za povezovanje procesorjev in mostov, iz katerega je nastal HyperTransport. Ta se je izkazal za tako učinkovitega, da ga danes najdemo celo v nekaterih chipsetih Nvidie in SiSa, namenjenih procesorju Xeon.
Vendar čudežno vodilo samo po sebi še ne reši vseh problemov. Potrebuje vsaj še procesor, ki ga zna polno izkoriščati. Seveda je AMD poskrbel tudi zanj. Tako imajo danes vsi AMDjevi x86_64 (ali kakorkoli jih že hočete poimenovati) procesorji najmanj dve HyperTransport povezavi, v strežniških izdajah pa kar pet:
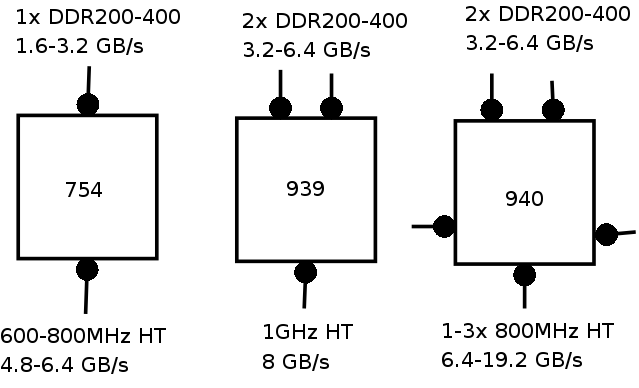
Značilnost Opteronov je tudi to, da pometejo s konceptom northbridgea in ustrezno logiko vključijo kar na procesorsko rezino. Tako termin FSB zgubi svoj pomen, če pa ga že najdemo uporabljenega, pa se nanaša na hitrost HyperTransporta. Ključ za skalabilnost Opteron 200/800 serije se skriva v dodatnih HyperTransport povezavah, s katerimi vsak procesor dobi direktno povezavo do dveh sosednjih, svojega RAMa in zunanjih I/O naprav. Primerjajmo to z mogoče bolj domačim sistemom, mrežo: Intelov AGTL+ bi lahko primerjali z ethernet hubom, EV6 z ethernet switchem, HyperTransport/NUMA pa izgleda kot direktne povezave s kabli med elementi.
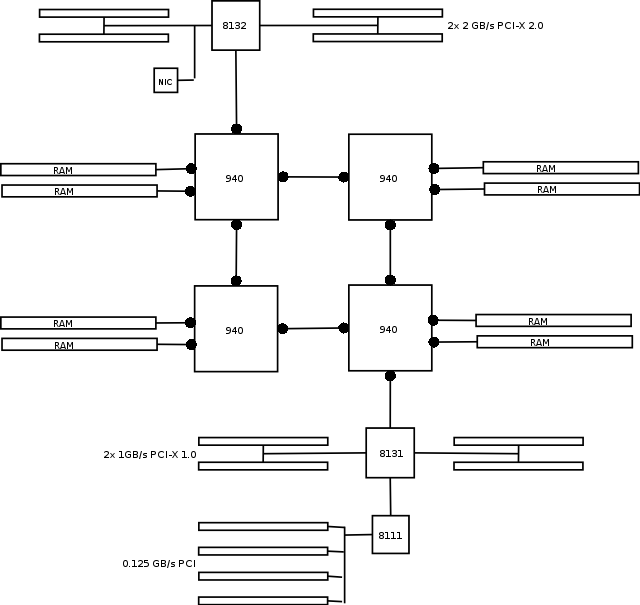
Kaj je razlog, da je vodilo do RAMa izvedeno mimo HyperTransporta? Poleg lažje NUMA implementacije še dejstvo, da tako hitrost pomnilnika ne vpliva na hitrost vodila, lahko deluje na različni frekvenci in ne vpliva na hitrost delovanja procesorja. Pa še ena cvetka: pri Xeon NUMA implementacijah, kjer procesorji še vedno komunicirajo drug z drugim preko FSBja, se v primeru, da mora en procesor dostopati do podatkov v pomnilniku drugega, FSB zaklene, dokler se ta dostop ne konča in tako prepreči izvajanje drugih medprocesorskih ali I/O komunikacij. Pri Opteronu s HyperTransportom pa je vsak procesor oddaljen od kateregakoli drugega največ en skok po ločeni povezavi, tako da do blokiranja celega sistema pri izmenjavi podatkov med pomnilniki ne more priti. Tudi koherentnost predpomnilnikov se izvaja po tej poti, pravtako pa je katerakoli povezava med I/Ojem in posameznim procesorjem lokalna temu procesorju. Tako se koncept CPU affinity razširi še na izvajanje I/O operacij in najpomebnejše, na "memory mapped I/O".
Na kaj moramo biti pozorni, ko se odločimo za nakup Opteron strežnika? Ker je Intel v poslovnem svetu še vedno referenca ("nobody got fired for buying Intel"), je AMD na žalost smatran kot cenejša alternativa. Nekateri izdelovalci plošč se za to še dodatno potrudijo in znižajo ceno svojim izdelkom tako, da jim okrnijo funkcionalnost. Take plošče prepoznamo po tem, da imajo kljub dvema procesorja le eno mesto za ram, kar pomeni, da eden od procesorjev dostopa do pomnilnika preko drugega, kar avtomatično pomeni slabše zmogljivosti. Ko torej iščemo plošče za Opterone, izbirajmo med modeli, ki ponujajo: vsak procesor ima svoj ram, plošča naj ponuja več PCI-X vodil in vsako izmed njih naj bo preko bridgea "obešeno" na svoj procesor. Kvalitetno ponudbo trenutno najdemo recimo pri Sunu in HPju.
Viri
Dissecting PC server performance,Great microprocessors of the past and present,
Linux Scalability Effort NUMA FAQ

Pentium 4 Extreme Edition
- Simon Belak ::
AMD je izpljunil svoje Athlone64, Intel pa nič. Njihovo edino železo v ognju je dobesedno to. Razbeljeno. Prihajajoči Prescotti so tako vsem najbolj poznani po naravnost fantastičnih količinah proizvedene toplote. Je velikan končno dobil zaušnico? Daleč od tega. ...

Pentium 4 3,2 GHz
- Simon Belak ::
Intel je, kot veste vsi, ki pridno berete naše novice, 23. junija predstavil svoj najnovejši umotvor, Pentium 4, ki tiktaka pri 3,2 GHz. Zadevščina se seveda predaja vsem trenutnim modnim smernicam in tako ima Hyper-Threading z zunanjim svetom pa se najraje pogovarja pri 800 MHz. ...

Procesorske tehnologije (II. del)
- Malecky ::
Slycer je pojasnil delovanje vsakega procesorja na osnovi Pentium 4, jaz se bom pa poglobil v stvari, ki so jih Intelovci razvijali pet let in ki naj bi bile revolucionarne, tudi par let pred vsakim konkurenčnim izdelkom. V tem poglavju se bomo osredotočili na razlike med Intel Pentium 4 in ...

Primerjava Athlonov XP
[st.slika 42115] Sredi maja leta Gospodovega 2001 je AMD premierno izdal procesor, ki je temeljil na novem jedru, katerega je AMD taktično poimenoval Athlon4. Pod kodnim imenom Palomino znani procesor naj bi ponujal več od legendarnega Thunderbirda, se manj grel ter bil nasploh prodajna uspešnica. ...

Test A64 Osnovnih plošč
- Babič Gregor ::
Eno leto je že minilo, odkar je AMD predstavil novo generacijo procesorjev, imenovanih Athlon 64, vendar se ti med uporabniki kar nekako niso hoteli prijeti. Glavni razlog je bila najbrž cena procesorjev, ki jo je AMD nastavil tako, da sledi cenam primerljivih Intelovih Pentium 4 procesorjev. Zmeda ...