AlphaGo Zero se uči brez človeškega zgleda
Slo-Tech - Ko je AlphaGo lani in letos rutinsko premagoval najboljše igralce goja na svetu, smo se lahko tolažili z dejstvom, da smo ga goja naučili igrati ljudje. AlphaGo je resda premagal najboljšega igralca na svetu, celotno internetno skupnost in korejskega prvaka, toda igre se je naučil z analizo tisočih odigranih partij med najboljšimi človeškimi igralci, potem pa je seveda svoje mojstrstvo izpilil z lastnim preračunavanjem in učenjem. Sedaj je Googlova podružnica DeepMind pokazala, da je za AlphaGo človeštvo povsem nepotrebno. Nova verzija AlphaGo Zero se je goja naučila sama, ne da bi sploh kdaj videla potek kakšne igre.
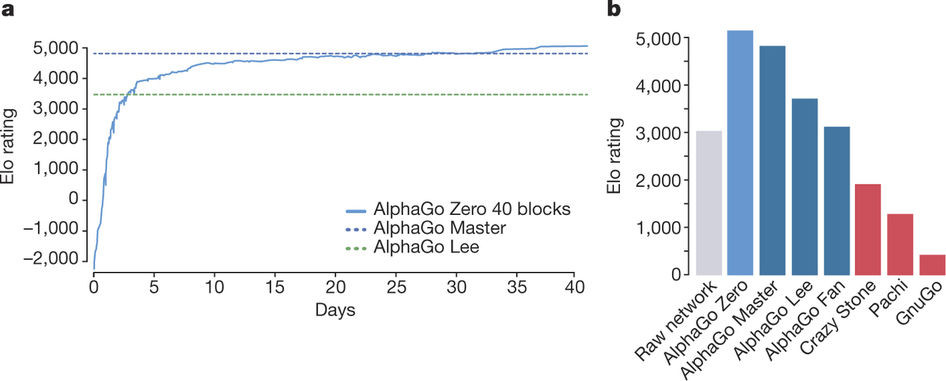
AlphaGo Zero je dobil samo pravila igre, potem pa se je igranja učil sam, tako da je igral sam proti sebi. Rezultati so osupljivi, saj je AlphaGo Zero v treh dneh iz popolnega začetnika napredoval do...
AlphaGo Zero je dobil samo pravila igre, potem pa se je igranja učil sam, tako da je igral sam proti sebi. Rezultati so osupljivi, saj je AlphaGo Zero v treh dneh iz popolnega začetnika napredoval do...

