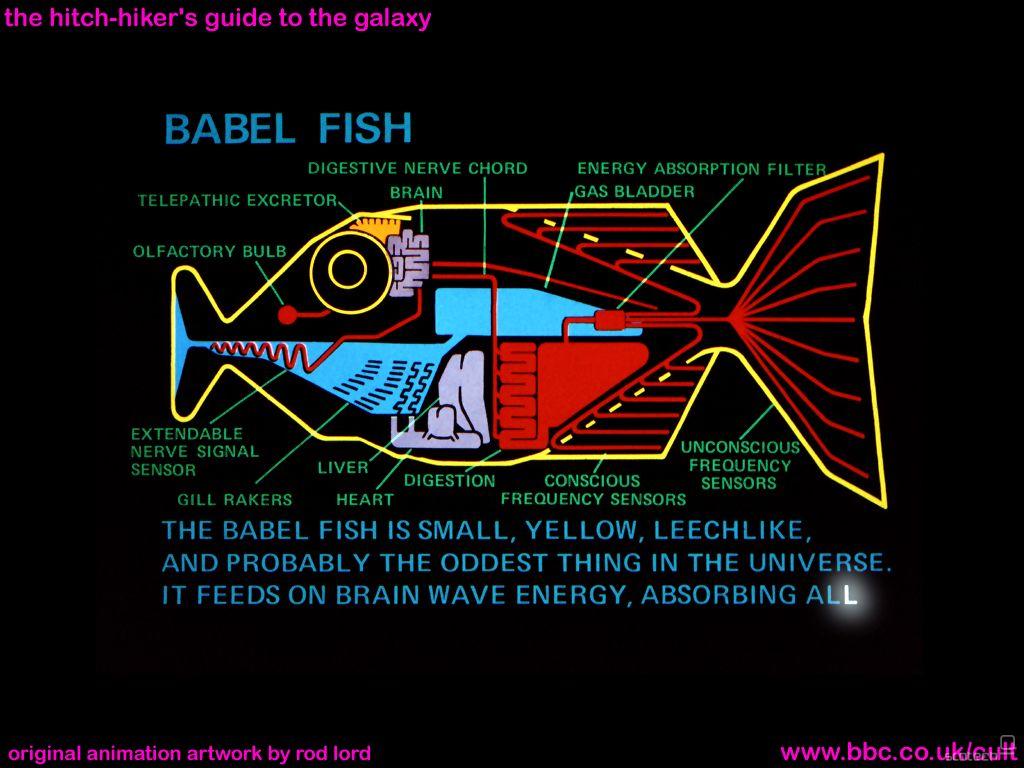
Times Online - Ribo babilonko si je zamislil Douglas Adams v Štoparskem vodniku po galaksiji. V originalu gre za majhno rumeno ribico, podobno pijavki, a v resničnosti se bomo zadovoljili s kakršnokoli formo, ki bo opravljala isto poslanstvo. Poizkusov ne manjka. Avtomatsko prevajanje zapisanega teksta deluje presenetljivo solidno, rezultate pa so dali že tudi prvi poizkusi programov, ki bo tolmačili govorjeni tekst. Omenimo program za iPhone profesorja s Carnegie Mellon University in Toshibino rešitev.
Reševanja tega problema se je lotil tudi velikan Google. Pri razvoju se bodo oprli na že obstoječe algoritme strojnega prevajanja teksta - lasten Googlov podpira že 52 jezikov - in tehnologijo za prepoznavanje govora. Ideja je izvesti prevajanje v paketih, kot to počno človeški tolmači. Franz Och, vodja Googlove prevajalske skupine, pravi, da lahko že v naslednjih nekaj letih pričakujemo dobro strojno prevajanje govorjene besede. Problem prepoznavanja govora, kjer sistema ne smejo zmesti unikatne karakteristike posameznika, kot so intonacija, naglas in barva glasu, naj bi bil na prenosnih telefonov lažje rešljiv. Ker telefon uporablja večinoma ena oseba, se bo programska oprema njenega glasu navadila, dodaja Och. Tako bi, vsaj v teoriji, telefon z daljšanjem uporabe prevajal vedno bolje.
Akademiki so bolj zadržani. Profesor jezikoslovja David Crystal z Bangor University meni, da problema prepoznavanja različnih naglasov v prihodnjih letih še ne bomo zadovoljivo rešili. Morda bo Googlu to uspelo prej kot ostalim, a gotovo ne v tako kratkem času, dodaja.
Js tud rečem da še dolgo dolgo nič nebo. Sj z googlom prevedenih strani se še zmer ne da brat npr. iz hrvaščine, ko nič ne znam, vseen raj v njihovem jeziku. Druga stvar je kitajščina
To da telefon vedno uporablja zgolj 1 oseba velja zgolj napol - prevajanje lastnika. Kaj pa prevajanje odgovora z druge strani "žice"? Ali se računa, da bo imel tudi sogovornik podoben software, ki bo delal isto?
Where all think alike, no one thinks very much.
Walter Lippmann, leta 1922, o predpogoju za demokracijo.
Govori pa lepo že Amazonov voice-to-speech na Lindlu in je samo vprašanje časa da google izpopolni svojega. Moje mnenje pa je da se bo to slej kot prej prijelo in pri tem še zmanjšalo naše znanje knižnjega jezika. Pa ne samo v Sloveniji ampak povsod se bo bolj strojno govorilo. Je pa Slovenščina zaradi sklanjanja, dvojine,... veliko bolj za*ebana za prevajat V kot kaki germanski jeziki. Potem romanski majo pa spet svoje fore. Da pa ne govorimo o razliki v Kitajščini ali Japonščini....
Z zrazliko da ta ribica ni nikoli prevajala samega govora v smislu voice-to-speach, ampak je kompajlala elektro valove, ki jih možgani oddajajo pri govoru. ...če me spomin ne vara :)
Je pa Slovenščina zaradi sklanjanja, dvojine,... veliko bolj za*ebana za prevajat V kot kaki germanski jeziki. Potem romanski majo pa spet svoje fore. Da pa ne govorimo o razliki v Kitajščini ali Japonščini....
Pa to si zdaj omenil samo slovnico, ko se pa spraviš na vse pomenske nianse, metafore, pregovore, lokalne fore, itd. ... Strojno prevajanje še kar nekaj časa ne bo na nivoju dobrega človeškega prevajalca, ki ima dovolj znanja o obeh jezikih in o obeh kulturah, v katerih prevaja.
In zakaj stroj ne more imeti tega znanja o kulturi, jezikih in navadah? Človeški prevajalec se tega nauči v letih, stroj pa mogoče v desetletjih, ampak pol je še copy/paste, ki traja 5 sekund.
Motiti se je človeško.
Motiti se pogosto je neumno.
Vztrajati pri zmoti je... oh, pozdravljen!
Saj nimam nič proti temu, da bi končno razvili "ribo babilonko", samo pravim, da je trenutno strojno prevajanje šele v povojih v primerjavi z dobrimi človeškimi prevajalci.
seveda ni tako preprosto (čeprav ok, take avte, ki jih danes vozimo bi tudi zelooo težko naredil takrat ko so se prvi pojavl) ampak nekje je treba začet in bomo vedno 20 let stran od dovolj dobre tehnologije če ne bomo nikoli začel ;)
jaz tudi recem, da prej kot v 6-7 letih ni variante, da bi to bilo neki uporabno... ceprav demnstracija od google wave-a je bila obetavna...
mislim pa, da ce bo google nadaljeval s skeniranjem vseh mogocih knjig (tudi v drugih jezikih)... in s svojo komputacijsko mocjo... boimel kmalu na voljo 99.9% vseh moznih jezikovnih kombinacij..., torej moral bo delat na tem, da bo dejansko razumel besedilo (kontekst)...in bo pravilno uporabljal vse sklone etc...
potem pa delal vzporedno se na tehnologijah za voice recognition in avtomatsko glede na par besed ugotoviti dialekt/barvo glasu/etc in tako servirati ustrezne prevode...
bo treba res se p[ar let, da bodo proci uspeli to realtime sprocesirat... (grafenski? )
torej 6-7 let da bi bilo vsaj uporabno, 10 let, da bo zanesljivo
Morda do "dobrega" translatorja niti ni tako daleč. Koneckoncev, v vsej literaturi verjetno težko najdeš poved, ki ni že bila prevedena. Če pa je kaka nova, pa prevajalnik pač prevede ad-hoc, tako, kot sedaj. V morju teksta itak nobeden ne bo opazil .
Kaj je treba naredit, je le poskenirat čim več knjig in gradiva, ki je identično v dveh jezikih (zgolj prevod), besedila cross-linkat, in naredit en hiter specializiran iskalnik.
Morda do "dobrega" translatorja niti ni tako daleč. Koneckoncev, v vsej literaturi verjetno težko najdeš poved, ki ni že bila prevedena. Če pa je kaka nova, pa prevajalnik pač prevede ad-hoc, tako, kot sedaj. V morju teksta itak nobeden ne bo opazil .
Kaj je treba naredit, je le poskenirat čim več knjig in gradiva, ki je identično v dveh jezikih (zgolj prevod), besedila cross-linkat, in naredit en hiter specializiran iskalnik.
še enkrat, ni tako enostavno .. niti s celimi povedmi ne prideš do pravilnega prevoda ... pomensko bo zgrešeno glede na ostalo besedilo, stavki ne bodo lepo tekli itd. .. z enostavnim copy paste ne bo šlo nikoli. Že Google translate je pametnejši od tega.
Morda do "dobrega" translatorja niti ni tako daleč. Koneckoncev, v vsej literaturi verjetno težko najdeš poved, ki ni že bila prevedena. Če pa je kaka nova, pa prevajalnik pač prevede ad-hoc, tako, kot sedaj. V morju teksta itak nobeden ne bo opazil .
Kaj je treba naredit, je le poskenirat čim več knjig in gradiva, ki je identično v dveh jezikih (zgolj prevod), besedila cross-linkat, in naredit en hiter specializiran iskalnik.
še enkrat, ni tako enostavno .. niti s celimi povedmi ne prideš do pravilnega prevoda ... pomensko bo zgrešeno glede na ostalo besedilo, stavki ne bodo lepo tekli itd. .. z enostavnim copy paste ne bo šlo nikoli. Že Google translate je pametnejši od tega.
valda da bi slo! ce bi poskenirali n poindexirali 50% knjig tega sveta bi po mojem pokrili 90% prevodov (dobesednih)....
potem rabis ene 5 dodatnih algoritmov oz. rutin..
1. ugotovi samostalnike, glagole, pridevnike in ostala dolocila 2. ugotovi spole, sklone, spregatve in case 3. ugotovi narecje, tujke, okrajsave 4. upostevaj uporabnikove navade.. uci se sproti 5. ugotovi kontekst (glede na prejsnje 3 tocke in seveda na ze prej vneseni tekst)
nic tezkega, samo rabi ogromno zacetnega gradiva in veliko komputacijsko moc...
ko enkrat pravilno in namensko zadeve poindeksira je veliko lazje in hitrejse...
pri pogovoru 2 ali vecih ljudi, pa 4. tocko vedno priredi, ko ugotovi kdo se pogovarja...
potem se lahko doda se 6. tocka in sicer dinamika pogovor teh 2 oseb... namrec jaz se z enim kolegom drugace pogovarjam kot z drugim (kake interne fore)... in s sefom ali kakim drugim uradnikom spet drugace pogovarjam!
malo vecji problem je to udejanit z inputom, ki ga dobis z voice recognition... naceloma veliko prej omenjenih tock lahko uporabis tudi za zelo natancen voice recognition
po mojem je vseskupaj le stvar casa in kopicenja podatkov - tako kot MAPS... jaz si 5 let nazaj nebi nikoli predstavljal, da bomo v roku 5ih let imeli tako dobre google mapse (sploh v US urbanih obmocjih)...
heh, ja .. recimo, da je samo teh 5 korakov, ki si jih napisal .. niti slučajno se jih pa ne da opisati z "nič težkega", ko hočeš to spravit v računalniški algoritem ...
heh, ja .. recimo, da je samo teh 5 korakov, ki si jih napisal .. niti slučajno se jih pa ne da opisati z "nič težkega", ko hočeš to spravit v računalniški algoritem ...
seveda da ni nic tezkega, ko imas zadosti gradiva.... ce ga nimas, potem je to zeloo tezko!
1. ugotovi samostalnike, glagole, pridevnike in ostala dolocila 2. ugotovi spole, sklone, spregatve in case 3. ugotovi narecje, tujke, okrajsave 4. upostevaj uporabnikove navade.. uci se sproti 5. ugotovi kontekst (glede na prejsnje 3 tocke in seveda na ze prej vneseni tekst)
evo, glihkar si napisal način, ki bi se komot uporabljal za črpanje vseh informacij iz človeških jezikov in pretvarjanja v računalniške jezike. ko maš vse te informacije popredalčkane in določena razmerja ter povezave med besedami in pojmi, maš tapravo umetno inteligenco.
tko da - ko bo google ali kdorkoli drug res razvil take algoritme za črpanje vseh informacij nekega teksta, kar je potrebno za dobre prevode, ne bo več dolgo do tehnološke singularnosti.
Nisem bral komentarjev , ampak Ray Kurzweil je že pred leti napovedal, da se bo speach to speach translation razvil. Falil je nekaj let, ampak zgodilo se pa očitno bo.
Jaz sem tudi nekaj let nazaj poudaril, da tehnologija že obstaja, vendar ni v wide use, tako, da se Ray sploh ni tako veliko zmotil v letih. Meni so se itak smejali, ko sem rekel, da verjamem, da bo to prišlo v splošno uporabo, ampak sem ostal trdnega mnenja, da je to tako poemembna funkcija, da kaj drugega sploh ni za pričakovati.
Da se je Google lotil tega prvi, me pa sploh ne preseneča. Ima namreč najbolj razvit sistem prevajanja teksta v različne jezike. Ameriški lastniki Nexus One pa pravijo, da speach recognition, dela neverjetno dobro.
Res super. Res pa je, da upam, da se poleg googla pojavi še kakšen ponudnik omenjenih storitev.
Islam is not about "I'm right, you're wrong," but "I'm right, you're dead!"
-Wole Soyinka, Literature Nobelist
|-|-|-|-|Proton decay is a tax on existence.|-|-|-|-|