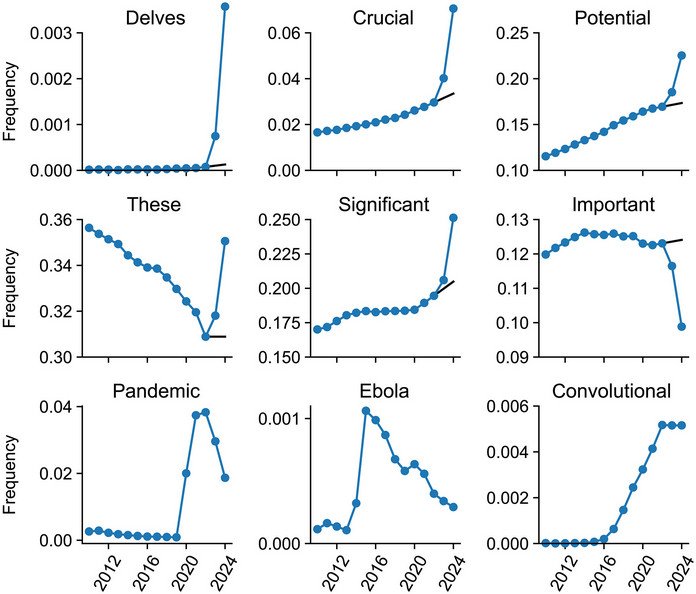
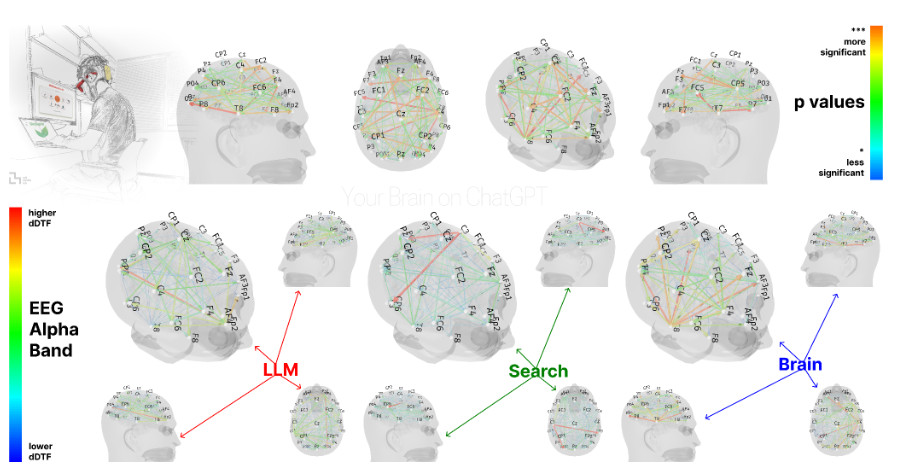
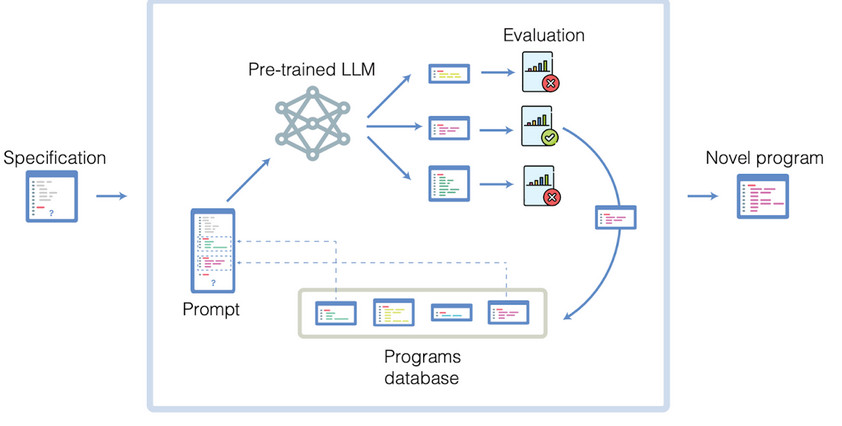
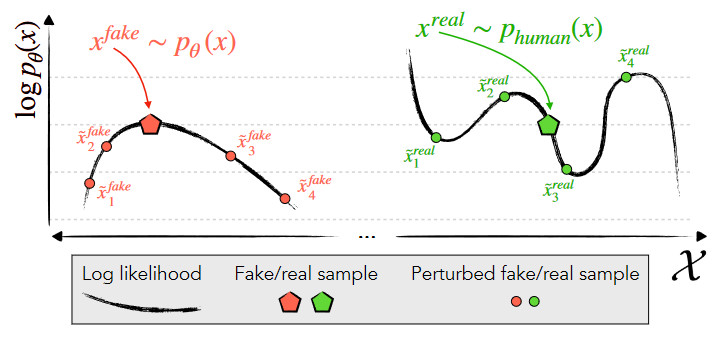
Wikipedia prepovedala uporabo velikih jezikovnih modelov

Slo-Tech - Angleška Wikipedia je sprejela uradno stališče, s katerim prepoveduje uporabo generativne umetne inteligence za ustvarjanje vsebin na strani. Pisanje ali večje popravljanje in izboljševanje člankov z modeli umetne inteligence ni dovoljeno, ker krši eno osnovnih načel spletne enciklopedije. Le v nekaterih primerih bo omejena uporaba LLM-jev dovoljena.
Uredniki bodo lahko z LLM-ji popravljali lastno besedilo, če ga bodo na to še temeljito prebrali in potrdili pristnost. Enako bo veljalo za prevode besedil, a mora urednik tekoče govoriti oba jezika in na koncu preveriti prevod še sam.
Wikipedia pa ni ena sama, temveč gre za zbirko skupnosti okoli vsakega jezika posebej. Zapisano velja za prispevke v angleščini. V španski verziji so na primer LLM-je popolnoma prepovedali, dovoljeni niso niti za prevajanje. Wikipedijin administrator Chaotic Enby je dejal, da se tako borijo proti vsesplošnemu slabšanju kakovosti (enshittification) in pritisku ponudnikov umetne inteligence. Ker pa...
Uredniki bodo lahko z LLM-ji popravljali lastno besedilo, če ga bodo na to še temeljito prebrali in potrdili pristnost. Enako bo veljalo za prevode besedil, a mora urednik tekoče govoriti oba jezika in na koncu preveriti prevod še sam.
Wikipedia pa ni ena sama, temveč gre za zbirko skupnosti okoli vsakega jezika posebej. Zapisano velja za prispevke v angleščini. V španski verziji so na primer LLM-je popolnoma prepovedali, dovoljeni niso niti za prevajanje. Wikipedijin administrator Chaotic Enby je dejal, da se tako borijo proti vsesplošnemu slabšanju kakovosti (enshittification) in pritisku ponudnikov umetne inteligence. Ker pa...