Googlov algoritem Veo 3 proizvaja generiran video s sinhroniziranim zvokom

vir: Google
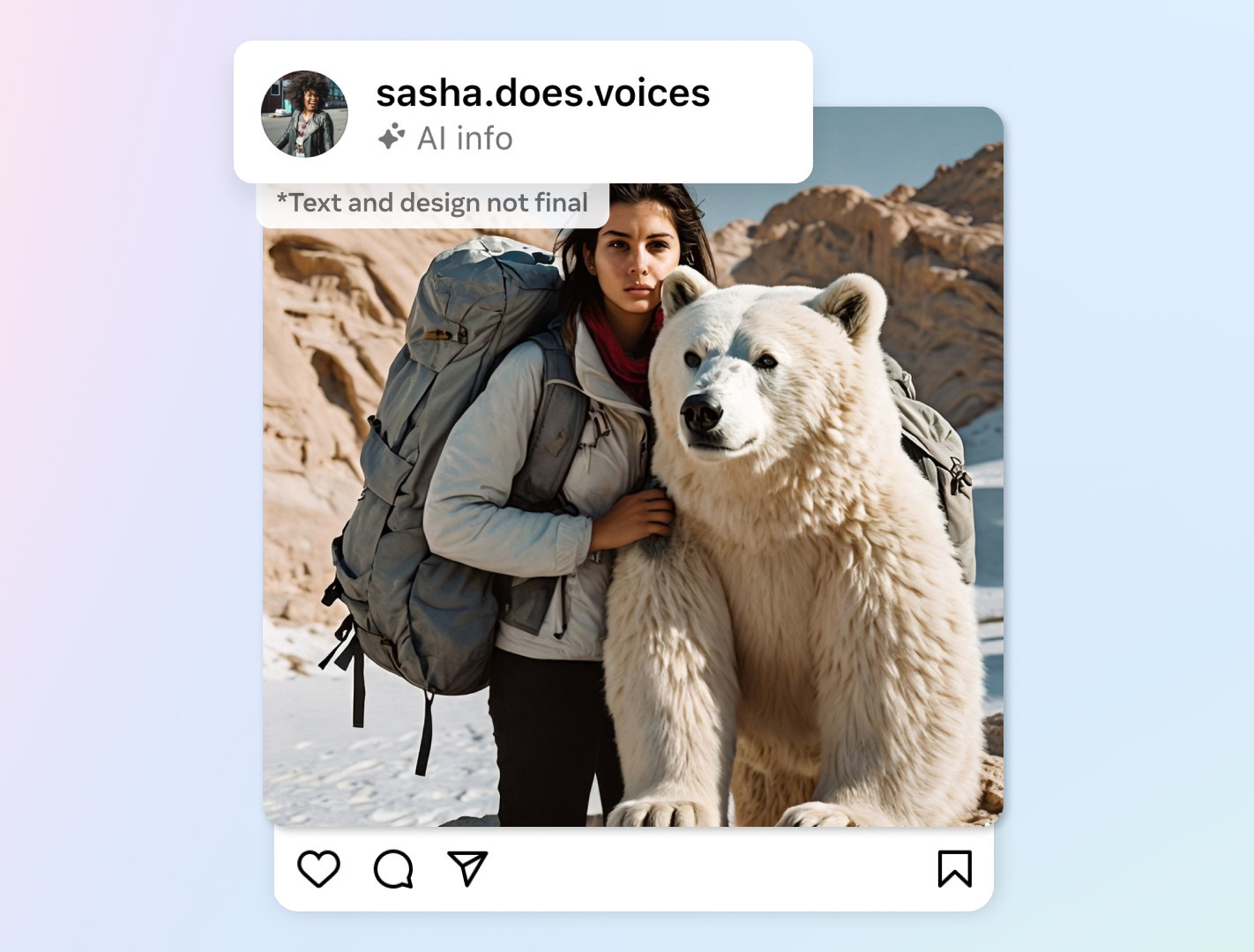
Google - Sredi tedna so pri Googlu lansirali tretjo generacijo svojega algoritma za generiranje videa Veo, ki se tokrat pošteno razlikuje od tekmecev v tem, da je zmožen gibljivim sličicam dodati primerno zgeneriran zvočni posnetek.
Od pomladi 2023, ko smo bili priče grotesknim podobam računalniško zgeneriranega Willa Smitha pri goltanju špagetov, so algoritmi za ustvarjanje video posnetkov napredovali z velikimi koraki. V približno dveh letih smo od posmeha vrednih izdelkov prišli do takšnih, kjer se je treba resno vprašati, ali bi jih bil povprečen uporabnik spleta res zmožen pravilno identificirati. Z najnovejšo, tretjo različico Googlovega algoritma Veo, je izziv postal še dodatno zapleten, ker je sposoben posnetku pripeti tudi govor ali zvok, kakršnega uporabnik zahteva s tekstovnim ukazom.
Pri tem ga sicer mestoma še lomi, saj denimo pade na hudomušnem testu Smithovega požiranja špagetov, ker ti hrustljajo. Toda z nekaj poizkušanja in sreče je mogoče napraviti posnetke, ki so že
Od pomladi 2023, ko smo bili priče grotesknim podobam računalniško zgeneriranega Willa Smitha pri goltanju špagetov, so algoritmi za ustvarjanje video posnetkov napredovali z velikimi koraki. V približno dveh letih smo od posmeha vrednih izdelkov prišli do takšnih, kjer se je treba resno vprašati, ali bi jih bil povprečen uporabnik spleta res zmožen pravilno identificirati. Z najnovejšo, tretjo različico Googlovega algoritma Veo, je izziv postal še dodatno zapleten, ker je sposoben posnetku pripeti tudi govor ali zvok, kakršnega uporabnik zahteva s tekstovnim ukazom.
Pri tem ga sicer mestoma še lomi, saj denimo pade na hudomušnem testu Smithovega požiranja špagetov, ker ti hrustljajo. Toda z nekaj poizkušanja in sreče je mogoče napraviti posnetke, ki so že