Forum » Strojna oprema » AMD razkril podrobnosti Bulldozer in Bobcat arhitektur
AMD razkril podrobnosti Bulldozer in Bobcat arhitektur
kihc ::
Tole naj bi bila novica, ampak nekako ni prišla na prvo stran, zato kopiram še sem.
--------------------------
Na 22. konferenci Hot Chips, katera vsako leto poteka na Stanfordski univerzi, je AMD razkril nekaj podrobnosti o zasnovi njegovih prihajajočih procesorjev. Pri Anandtechu so spisali obširen članek na to temo.
Naj ponovimo, AMD pripravlja nove procesorje za vse tri segmente trga (low end/low power, mainstream, high end), temelječe na arhitekturah Bobcat, Llano in Bulldozer. Kjer bo Lliano le derivat obstoječega Phenoma II, so pri preostalih dveh AMDjevi inženirji konkretno zavihali rokave.
Bobcat - Atom s podporo dinamičnemu razvrščanju ukazov
Zaradi želje po zmanjšanju porabe energije je bil Atom prvi Intelov procesor po P6, ki ni podpiral neurejenega izvajanja ukazov, čeprav omenjena tehnika zaradi izogibanja podatkovnim nevarnostnim zmanjša zastoje v cevovodu in posledično precej pripomore k zmogljivosti stroja.
AMD želi z vpeljavo te tehnike v svoje nizko energijske procesorje zmanjšati razlike v zmogljivosti netbook/nettop računalnikov in njihovimi polnokrvnimi brati, oziroma izboljšati razmerje med zmogljivostjo in porabo energije, s tem pa predstavlja konkurenco tudi Intelovim CULV procesorjem. Glede na to, da so ostali detajli mikroarhitekture (z izjemo več nitnosti, katere Bobcat jedro ne podpira, in implementacije preimenovanja registrov na bolj energijsko varčen način) skupaj s taktom procesorja identični Atomu, lahko pričakujemo opazen dvig zmogljivosti.
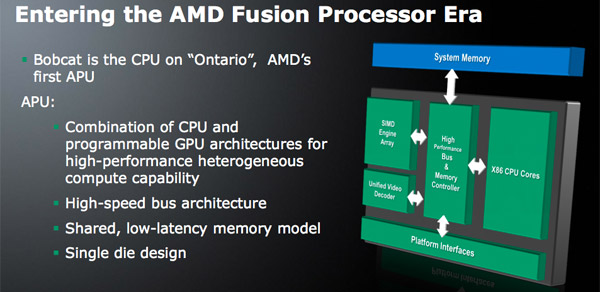
Bobcat bo za razliko od Atoma naprodaj le v integrirani obliki, na silicijevi rezini pa bo vedno še grafično jedro. Prvo manifestacijo nove arhitekture bo tako predstavljal Ontario, kateri bo vseboval dve Bobcat jedri, podrobnosti o grafičnem jedru pa ostajajo še skrite. Izdelan bo v 40nm tehniki (Atomi so izdelani v 45nm) in bo tako TSMCjev prvi x86 procesor, dobavljiv pa naj bi bili okrog novega leta.
Buldožer
Bulldozer prinaša veliko novost na področju simultanega izvajanja več (če smo natančni dveh) niti na enem procesorskem jedru. Namesto enega razvrščevalnika in izvršilne enote za celoštevilčne operacije in enega razvrščevalnika in izvršilne enote za operacije v plavajoči vejici (kar AMD poimenuje tudi celoštevilčno jedro in jedro za delo s plavajočo vejico), ima Bulldozer eno celoštevilčno jedro več. AMD trdi, da so na ta način relativno malo povečali velikost ene sredice (+12%), ampak konkretno pripomogli k hitrosti izvajanja dveh niti hkrati (seveda se predpostavlja, da uporabnik izvaja večji delež celoštevilčnih operacij).
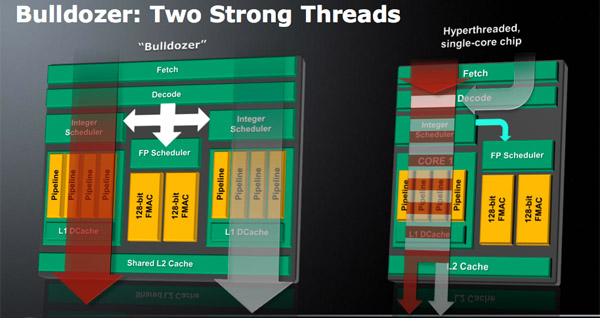
Vsako celoštevilčno jedro bo imelo po 16 KB lastnega L1 predpomnilnika, dvo vhodna enota za delo s plavajočo vejico pa bo lahko brala podatke z obeh. Vsa tri "jedra" si bodo delila skupen L2 predpomnilnik.
Razlike v mikroarhitekturi bodo še daljši cevovod, posledično izboljšano napovedovanje skokov in agresivnejši vnaprejšni bralnik ukazov.
Končni izdelki bodo vsebovali od 1 do 4 takšna jedra in bodo klasificirani kot 4 do 8 jedrniki. Poleg tega bodo novi procesorji vsebovali ekvivalent Intelovemu Turbo Boostu, ki omogoča izklop posameznih jeder (torej parov jeder po standardni klasifikaciji) v aplikacijah z nizko stopnjo paralelnosti in dvig takta preostalih jeder.
Datuma izida Buldožerja s strani AMDja ni bilo, se pa špekulira da bo to enkrat poleti 2011. Procesorji bodo izdelani v 32nm tehnologiji.
Komentarji?
Meni se zdi da Bobcat ima dober potencial, prav tako Llano za mainstream home/business kište. Glede buldožerja sem bolj skeptičen, nikakor mi ni všeč to da vsako buldozer jedro nazivajo 2 jedrno, čeprav je ubistvu 1,5 jedrno.
--------------------------
Na 22. konferenci Hot Chips, katera vsako leto poteka na Stanfordski univerzi, je AMD razkril nekaj podrobnosti o zasnovi njegovih prihajajočih procesorjev. Pri Anandtechu so spisali obširen članek na to temo.
Naj ponovimo, AMD pripravlja nove procesorje za vse tri segmente trga (low end/low power, mainstream, high end), temelječe na arhitekturah Bobcat, Llano in Bulldozer. Kjer bo Lliano le derivat obstoječega Phenoma II, so pri preostalih dveh AMDjevi inženirji konkretno zavihali rokave.
Bobcat - Atom s podporo dinamičnemu razvrščanju ukazov
Zaradi želje po zmanjšanju porabe energije je bil Atom prvi Intelov procesor po P6, ki ni podpiral neurejenega izvajanja ukazov, čeprav omenjena tehnika zaradi izogibanja podatkovnim nevarnostnim zmanjša zastoje v cevovodu in posledično precej pripomore k zmogljivosti stroja.
AMD želi z vpeljavo te tehnike v svoje nizko energijske procesorje zmanjšati razlike v zmogljivosti netbook/nettop računalnikov in njihovimi polnokrvnimi brati, oziroma izboljšati razmerje med zmogljivostjo in porabo energije, s tem pa predstavlja konkurenco tudi Intelovim CULV procesorjem. Glede na to, da so ostali detajli mikroarhitekture (z izjemo več nitnosti, katere Bobcat jedro ne podpira, in implementacije preimenovanja registrov na bolj energijsko varčen način) skupaj s taktom procesorja identični Atomu, lahko pričakujemo opazen dvig zmogljivosti.
Bobcat bo za razliko od Atoma naprodaj le v integrirani obliki, na silicijevi rezini pa bo vedno še grafično jedro. Prvo manifestacijo nove arhitekture bo tako predstavljal Ontario, kateri bo vseboval dve Bobcat jedri, podrobnosti o grafičnem jedru pa ostajajo še skrite. Izdelan bo v 40nm tehniki (Atomi so izdelani v 45nm) in bo tako TSMCjev prvi x86 procesor, dobavljiv pa naj bi bili okrog novega leta.
Ontario APU
Buldožer
Bulldozer prinaša veliko novost na področju simultanega izvajanja več (če smo natančni dveh) niti na enem procesorskem jedru. Namesto enega razvrščevalnika in izvršilne enote za celoštevilčne operacije in enega razvrščevalnika in izvršilne enote za operacije v plavajoči vejici (kar AMD poimenuje tudi celoštevilčno jedro in jedro za delo s plavajočo vejico), ima Bulldozer eno celoštevilčno jedro več. AMD trdi, da so na ta način relativno malo povečali velikost ene sredice (+12%), ampak konkretno pripomogli k hitrosti izvajanja dveh niti hkrati (seveda se predpostavlja, da uporabnik izvaja večji delež celoštevilčnih operacij).
Bulldozer jedro
Vsako celoštevilčno jedro bo imelo po 16 KB lastnega L1 predpomnilnika, dvo vhodna enota za delo s plavajočo vejico pa bo lahko brala podatke z obeh. Vsa tri "jedra" si bodo delila skupen L2 predpomnilnik.
Razlike v mikroarhitekturi bodo še daljši cevovod, posledično izboljšano napovedovanje skokov in agresivnejši vnaprejšni bralnik ukazov.
Končni izdelki bodo vsebovali od 1 do 4 takšna jedra in bodo klasificirani kot 4 do 8 jedrniki. Poleg tega bodo novi procesorji vsebovali ekvivalent Intelovemu Turbo Boostu, ki omogoča izklop posameznih jeder (torej parov jeder po standardni klasifikaciji) v aplikacijah z nizko stopnjo paralelnosti in dvig takta preostalih jeder.
Datuma izida Buldožerja s strani AMDja ni bilo, se pa špekulira da bo to enkrat poleti 2011. Procesorji bodo izdelani v 32nm tehnologiji.
Komentarji?
Meni se zdi da Bobcat ima dober potencial, prav tako Llano za mainstream home/business kište. Glede buldožerja sem bolj skeptičen, nikakor mi ni všeč to da vsako buldozer jedro nazivajo 2 jedrno, čeprav je ubistvu 1,5 jedrno.
x
Wrop ::
Koliko jeder bo imel buldožer je odvisno kako gledaš. Če bosta tekli dve niti, ki imata samo integer operacije, bo to videti kot da sta dve jedri. Vsaka nit ima svoj razvrščevalnik in ker gre vsaka nit v svoje jedro ne bo prihajalo do tega, da bi morala druga nit čakati, da se ALU ali AGU sprosti, ker bo ALU in AGU vedno na voljo. Število operacij na sekundo bi se teoretično moralo podvojiti. Pri plavajoči vejici je pa drugače. Tukaj si jedri delita dve enoti za FP. Tukaj bo zelo odvisno od razvrščevalnika. Ker samo delovanje razvrščevalnika ne poznam, lahko pa samo sklepam, bi upal reči, da bi lahko tudi podvojili hitrost SIMD+FP ukazov, kot je sedaj (phenom). Seveda v najboljšem primeru. Če bi ena nit imela samo FP ukaze, druga nit pa SSE ukaze.
Če bi pa obe niti imeli FP ukaze, pa bi si morali deliti en FP razvrščevalnik in dve enoti za računanje FP.
Bom v naslednjem postu malo bolj probal razložiti kako si mislim, da deluje buldožer modul.
Če bi pa obe niti imeli FP ukaze, pa bi si morali deliti en FP razvrščevalnik in dve enoti za računanje FP.
Bom v naslednjem postu malo bolj probal razložiti kako si mislim, da deluje buldožer modul.
Wrop ::
Kot sem rekel bom probal razložiti malo bolj to buldožer jedro. Seveda, ker zaradi pomankanja informacij (verjetno tudi zaradi konkurence), bom verjetno tudi kaj napačno povedal, za to seže vnaprej opravičujem.
Najprej kratek opis modula. Modul bo sposoben hkrati obdelovati dve niti. Če sem prav razumel, bo lahko bral iz dveh različnih pomnilniških naslovov istočasno(dve niti). Lahko pa samo iz enega(ena nit). Imel bo štiri dekoderje (enega več kot phenom 2). Modul bo imel 3 razvrščevalnike. Dva za integer in enega za FP (SIMD ukaze). Če v enem modulu delovala samo ena nit, bo kot pri phenomu 2. No ne bo čisto enako, ker imamo en ALU in AGU manj.
Integer razvrščevalnik ima 4 cevovode, 2 cevovoda za AGU, 2 cevovoda za dve ALU, en MUL in en DIV. Skupen pa bo razvrščevalnik. Verjetno je večji, bolj zapleten, a še vedno manjši kot, da bi bila dva. Pri phenomu 2, ki ima 3 ALE, lahko hkrati računa do 3 neodvisne operacije naenkrat. Do toliko neodnisnih operacij, verjetno ne pride prav velikokrat, zato se bolj splača izvajanje dveh niti, kot iskanje podatkovne neodvisnoti med ukazi.
Pri buldožerju se lahko hkrati izvajale 4 integer operacije na jedro. Na sliki vidimo 4 cevovode. 2 sta namenjena za računanje naslovov. 2 cevovoda pa za integer operande. Po sliki sodeč(2xALU zgoraj, MUL in DIV spodaj) bosta lahko hkrati vstopili dve operaciji seštevanja ali eno množenje eno deljenje ali seštevanje deljenje ali seštevanje množenje. Po pravici povedano ne vem, ker ni bolj podrobne sheme. Mislim, da se enostavnje operacije izvedejo v enem ciklu, množenje in deljenje pa v več ciklih. Pa če prav vem, je tudi množenje in razdeljeno na več podoperacij (cevovodno). Torej je lahko več ukazov v MUL enoti. Se pravi v dva INT cevovoda lahko naenkrat vsopita dve operaciji. Izvaja pa se jih lahko več (npr. vstopita dve operaciji seštevanja, od prej pa se še izvaja ena operacija množenja). Koliko končanih operacij lahko izstopi iz teh 4 cevovodov na urino periodo ne bi vedel (verjetno da 4). Lahko pa celo, da lahko naenkrat vstopijo 4 operacije (2xALE, MUL in DIV). TO bo mogoče kdo drug vedel bolj prav povedat.
FP razvrščevalnik si jedra delita. Ta del ima 2xMMX, torej računanje SSEx ukazov(2x128 bit) in 2xFMAC. Koliko je ta del zmogljiv je odvistno od same strukture in razvrščevalnika. Dam pa roko v ogenj, če ne bo bolje izkoriščen ta del, kot pri phenomu 2. Če primerjamo z Phenomom 2, imamo FP del enak.
Ker je SIMD ukazov in FP procentualno manj(čez zelo debel prst tam 10%) kot INT, ga lahko delimo z drugim jedrom, ker je tako ali tako veliko časa neizkoriščen. Sedaj ne vem koliko SIMD in FP operacij je arhitektura zmožna vstaviti v ta del v eni periodi(mislim da 2xFP in 2xINT(128bit)). V najboljšem primeru imamo dva ukaza za plavajočo vejico in dva ukaza za SIMD. Vse skupaj 512 bitov. Seveda je tudi pri teh operacij prisoten cevovod. Če sem prav razumel bosta lahko niti hkrati uprabljali ta del, pod podogjem, da ena uporabla INT SSE, druga pa FP in FP SSE. Ali pa njihove kombinacije. Drugače bodo operacije čakale. Če vzamemo, da imamo samo INT SSE ukaze, bo verjetno iz vsake niti pobrani dve operaciji. Nato se ugotovi podatkovno nevarnost. Če je ni, potem ena nit v trentnem ciklu zasede obe MMX enoti. V naslednjem ciklu druga, če seveda ni podatkovne nevarnosti. Vsakič FP razvrščevalnik pri obeh nitih pregleda podatkovno nevarnost in MMX enoti dobi tista nit, ki bi zasedla več MMX enot hkrati (če isto, potem se zamenjata). To predvsem zmanjšamo možnost podatkovnih nevarnosti oz. izboljšamo izkoriščenost.
Kako bo v resnici delovalo, je seveda vprašanje. Ampak če so pametno naredili, bo lahko hudičevo hiter.
Zato se jaz ne ni ravno najbolj strinjal, da je buldožer bistvu 1,5 jedrno.
Če še primerjam z intelovim HyperThreading-om. Kot vem, tam z enim jedrom hočejo čim bolj zapolniti z delom izvršilne enote. To se z dvemi nitmi kar lepo da, samo je pa treba vedet, da če imata dve niti istočasno isti tip operacij (npr. INT), bodo enote v celoti zasedene in se bosta niti mogli čakati. Če prav vem, ima tri INT ALE. Se pravi v najboljšem primeru lahko eno jedro(dve niti) izvede 3 INT operacije. Pri buldožerju je to 4 INT operacije. Kako bo v resnici je pa seveda drugo vrašanje. Zelo veliko je odvisno od razvrščevalnika. Na sliki se vidi lepo. Živi pa videli.
Najprej kratek opis modula. Modul bo sposoben hkrati obdelovati dve niti. Če sem prav razumel, bo lahko bral iz dveh različnih pomnilniških naslovov istočasno(dve niti). Lahko pa samo iz enega(ena nit). Imel bo štiri dekoderje (enega več kot phenom 2). Modul bo imel 3 razvrščevalnike. Dva za integer in enega za FP (SIMD ukaze). Če v enem modulu delovala samo ena nit, bo kot pri phenomu 2. No ne bo čisto enako, ker imamo en ALU in AGU manj.
Integer razvrščevalnik ima 4 cevovode, 2 cevovoda za AGU, 2 cevovoda za dve ALU, en MUL in en DIV. Skupen pa bo razvrščevalnik. Verjetno je večji, bolj zapleten, a še vedno manjši kot, da bi bila dva. Pri phenomu 2, ki ima 3 ALE, lahko hkrati računa do 3 neodvisne operacije naenkrat. Do toliko neodnisnih operacij, verjetno ne pride prav velikokrat, zato se bolj splača izvajanje dveh niti, kot iskanje podatkovne neodvisnoti med ukazi.
Pri buldožerju se lahko hkrati izvajale 4 integer operacije na jedro. Na sliki vidimo 4 cevovode. 2 sta namenjena za računanje naslovov. 2 cevovoda pa za integer operande. Po sliki sodeč(2xALU zgoraj, MUL in DIV spodaj) bosta lahko hkrati vstopili dve operaciji seštevanja ali eno množenje eno deljenje ali seštevanje deljenje ali seštevanje množenje. Po pravici povedano ne vem, ker ni bolj podrobne sheme. Mislim, da se enostavnje operacije izvedejo v enem ciklu, množenje in deljenje pa v več ciklih. Pa če prav vem, je tudi množenje in razdeljeno na več podoperacij (cevovodno). Torej je lahko več ukazov v MUL enoti. Se pravi v dva INT cevovoda lahko naenkrat vsopita dve operaciji. Izvaja pa se jih lahko več (npr. vstopita dve operaciji seštevanja, od prej pa se še izvaja ena operacija množenja). Koliko končanih operacij lahko izstopi iz teh 4 cevovodov na urino periodo ne bi vedel (verjetno da 4). Lahko pa celo, da lahko naenkrat vstopijo 4 operacije (2xALE, MUL in DIV). TO bo mogoče kdo drug vedel bolj prav povedat.
FP razvrščevalnik si jedra delita. Ta del ima 2xMMX, torej računanje SSEx ukazov(2x128 bit) in 2xFMAC. Koliko je ta del zmogljiv je odvistno od same strukture in razvrščevalnika. Dam pa roko v ogenj, če ne bo bolje izkoriščen ta del, kot pri phenomu 2. Če primerjamo z Phenomom 2, imamo FP del enak.
Ker je SIMD ukazov in FP procentualno manj(čez zelo debel prst tam 10%) kot INT, ga lahko delimo z drugim jedrom, ker je tako ali tako veliko časa neizkoriščen. Sedaj ne vem koliko SIMD in FP operacij je arhitektura zmožna vstaviti v ta del v eni periodi(mislim da 2xFP in 2xINT(128bit)). V najboljšem primeru imamo dva ukaza za plavajočo vejico in dva ukaza za SIMD. Vse skupaj 512 bitov. Seveda je tudi pri teh operacij prisoten cevovod. Če sem prav razumel bosta lahko niti hkrati uprabljali ta del, pod podogjem, da ena uporabla INT SSE, druga pa FP in FP SSE. Ali pa njihove kombinacije. Drugače bodo operacije čakale. Če vzamemo, da imamo samo INT SSE ukaze, bo verjetno iz vsake niti pobrani dve operaciji. Nato se ugotovi podatkovno nevarnost. Če je ni, potem ena nit v trentnem ciklu zasede obe MMX enoti. V naslednjem ciklu druga, če seveda ni podatkovne nevarnosti. Vsakič FP razvrščevalnik pri obeh nitih pregleda podatkovno nevarnost in MMX enoti dobi tista nit, ki bi zasedla več MMX enot hkrati (če isto, potem se zamenjata). To predvsem zmanjšamo možnost podatkovnih nevarnosti oz. izboljšamo izkoriščenost.
Kako bo v resnici delovalo, je seveda vprašanje. Ampak če so pametno naredili, bo lahko hudičevo hiter.
Zato se jaz ne ni ravno najbolj strinjal, da je buldožer bistvu 1,5 jedrno.
Če še primerjam z intelovim HyperThreading-om. Kot vem, tam z enim jedrom hočejo čim bolj zapolniti z delom izvršilne enote. To se z dvemi nitmi kar lepo da, samo je pa treba vedet, da če imata dve niti istočasno isti tip operacij (npr. INT), bodo enote v celoti zasedene in se bosta niti mogli čakati. Če prav vem, ima tri INT ALE. Se pravi v najboljšem primeru lahko eno jedro(dve niti) izvede 3 INT operacije. Pri buldožerju je to 4 INT operacije. Kako bo v resnici je pa seveda drugo vrašanje. Zelo veliko je odvisno od razvrščevalnika. Na sliki se vidi lepo. Živi pa videli.
Vredno ogleda ...
| Tema | Ogledi | Zadnje sporočilo | |
|---|---|---|---|
| Tema | Ogledi | Zadnje sporočilo | |
| » | Kaj je Hyper-threadingOddelek: Strojna oprema | 1988 (1696) | PARTyZAN |
| » | Novi procesorji iz AMD-jaOddelek: Novice / Procesorji | 12617 (10514) | bdoxx |
| » | AMD razkril podrobnosti Bulldozer in Bobcat arhitektur (strani: 1 2 3 )Oddelek: Novice / Procesorji | 32638 (29805) | Lonsarg |
| » | Računalništvo na maturi - več vprašanj, da vidimo kolko znate!Oddelek: Šola | 5321 (3393) | seaclam |