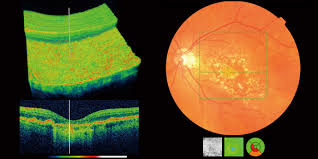
Umetna inteligenca na urgenci že podobno zmožna kot zdravniki
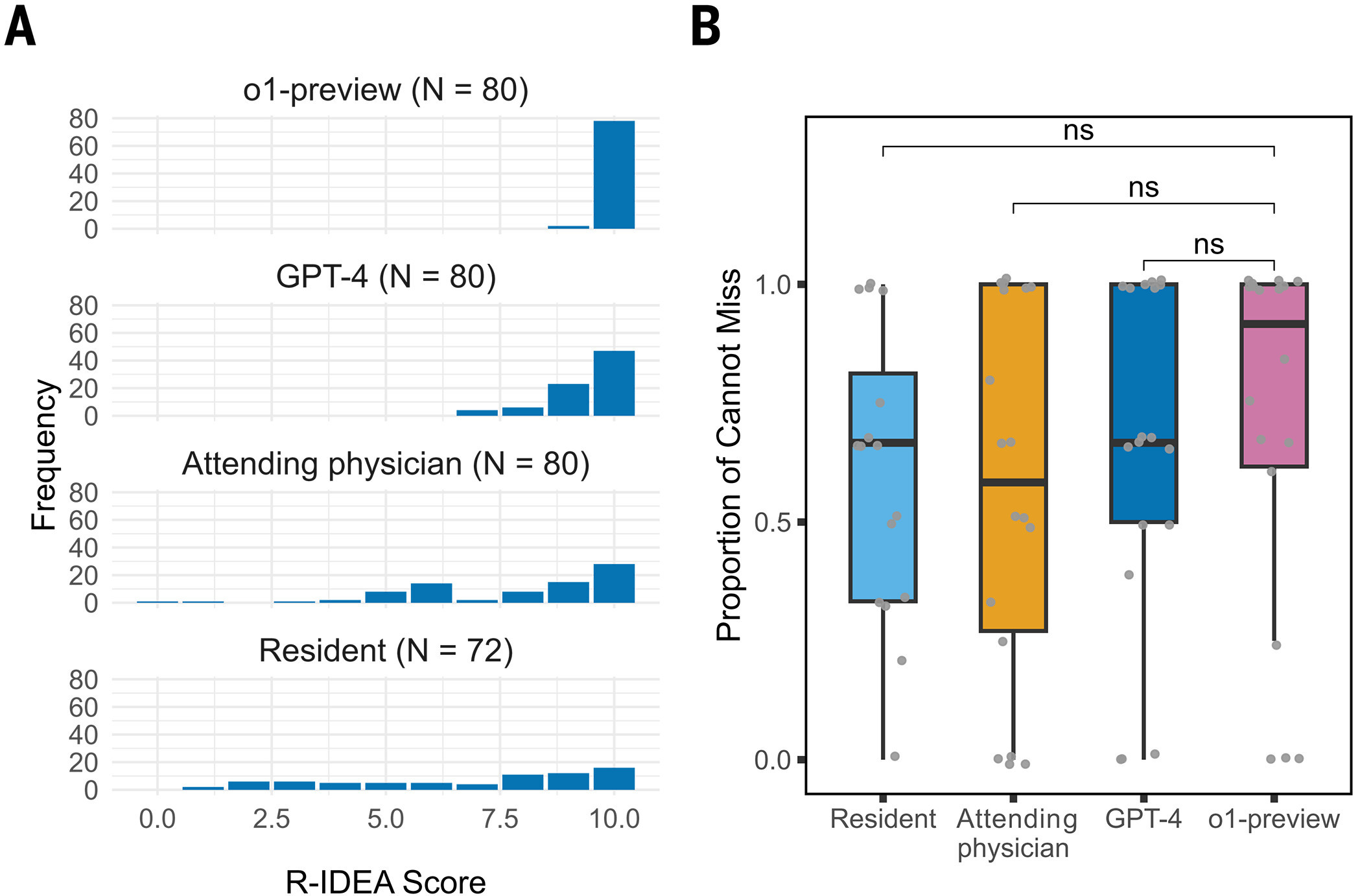
Slo-Tech - Raziskovalci s harvardske univerze in univerzitetnega kliničnega centra v Bostonu (Beth Israel Deaconess Medical Center) so razvili in preizkusili model umetne inteligence o1-preview, ki je bil prilagojen za diagnostiko bolnikov. Ugotovili so, da je bil v povprečju boljši od dveh izkušenih zdravnikov, s katerima so ga primerjali. Preizkušali so ga na svežih realnih primerih.
Novi OpenAI-jev model so preizkušali v več okoljih, od triaže na urgenci do diagnostike po sprejemu. V nekaterih primerih je imel pred seboj bolnike, ki so prišli po pomoč, v drugih primerih pa je analiziral objavljene primere v New England Journal of Medicine. V vseh primerih se je model zanašal izključno na besedilo, torej na izvide in druge pisne podatke, medtem ko ima zdravnik pred seboj bolnika in številne druge vire informacij, od videza, pogovora do neverbalnih znakov.
Tehnologija je napredovala. Novi model so primerjali tudi s starejšim GPT-4, katerega je za šalo premagal. Ob tem so avtorji raziskave...
Novi OpenAI-jev model so preizkušali v več okoljih, od triaže na urgenci do diagnostike po sprejemu. V nekaterih primerih je imel pred seboj bolnike, ki so prišli po pomoč, v drugih primerih pa je analiziral objavljene primere v New England Journal of Medicine. V vseh primerih se je model zanašal izključno na besedilo, torej na izvide in druge pisne podatke, medtem ko ima zdravnik pred seboj bolnika in številne druge vire informacij, od videza, pogovora do neverbalnih znakov.
Tehnologija je napredovala. Novi model so primerjali tudi s starejšim GPT-4, katerega je za šalo premagal. Ob tem so avtorji raziskave...