DeepMindov algoritem MuZero se uči kot otrok

vir: DeepMind
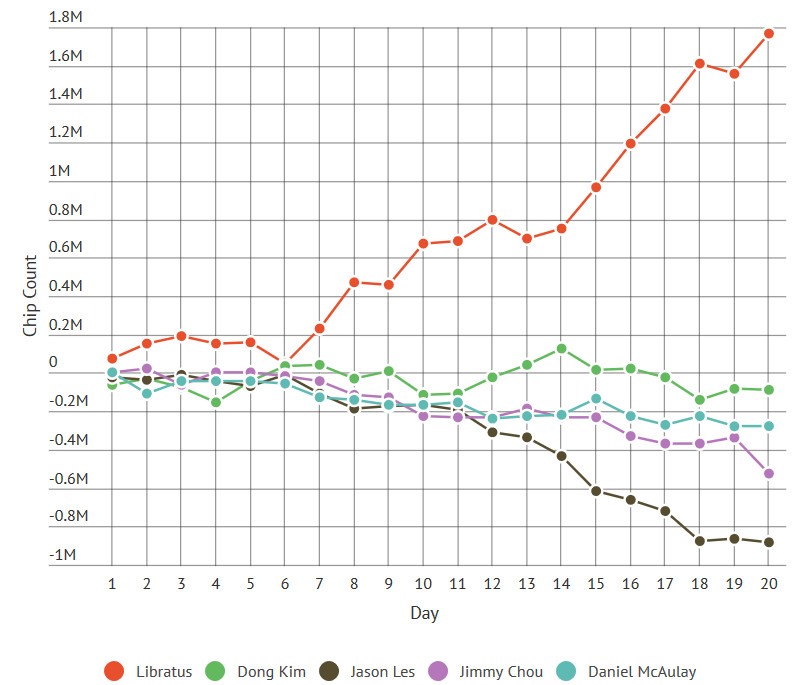
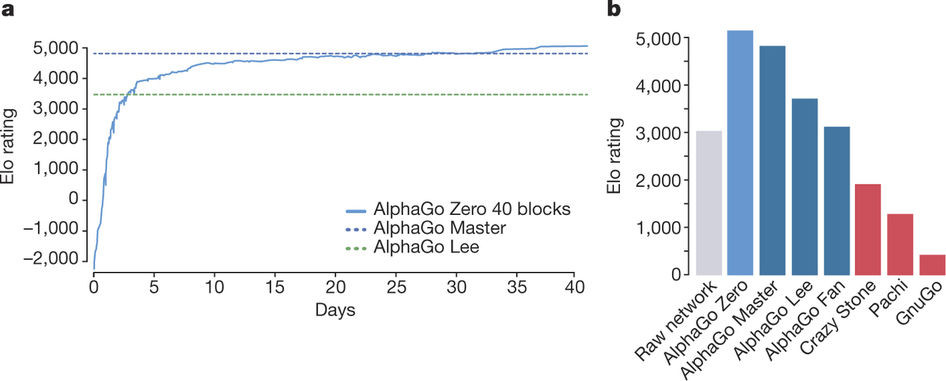
DeepMind - Alphabetov laboratorij za strojno inteligenco DeepMind je izgotovil nov algoritem, ki se je na samosvoj način izmojstril v igranju šaha, goja, šogija in Atarijevih arkadnih iger. Za učenje ne potrebuje predhodnega branja navodil ali vdelanih izkušenj, temveč se uči na podoben način kot otroci, s preizkušanjem posameznih potez in grajenjem notranjega modela igre, kar pomeni novo stopnjo v razvoju strojnih algoritmov z zmožnostjo posplošenega sklepanja.
Napredovanje DeepMindovih strojnih algoritmov je za nepoučenega opazovalca verjetno videti kot dolgočasno zbiranje naslovov prvaka v raznoraznih igrah. Toda zadaj se skriva zanimivo preizkušanje različnih pristopov k obvladovanju izzivov, ki nas utegnejo nekoč pripeljati do umetne inteligence, ki se bo znala odločati in učiti podobno kot človek. Sloviti AlphaGo, ki je v igri go nadvladal človeka, je - podobno kot šahovski algoritmi - uporabljal napredno različico drevesa dogodkov, ki za množico potez v prihodnosti pove predvideni...
Napredovanje DeepMindovih strojnih algoritmov je za nepoučenega opazovalca verjetno videti kot dolgočasno zbiranje naslovov prvaka v raznoraznih igrah. Toda zadaj se skriva zanimivo preizkušanje različnih pristopov k obvladovanju izzivov, ki nas utegnejo nekoč pripeljati do umetne inteligence, ki se bo znala odločati in učiti podobno kot človek. Sloviti AlphaGo, ki je v igri go nadvladal človeka, je - podobno kot šahovski algoritmi - uporabljal napredno različico drevesa dogodkov, ki za množico potez v prihodnosti pove predvideni...