Veliki jezikovni modeli verjamejo lažem
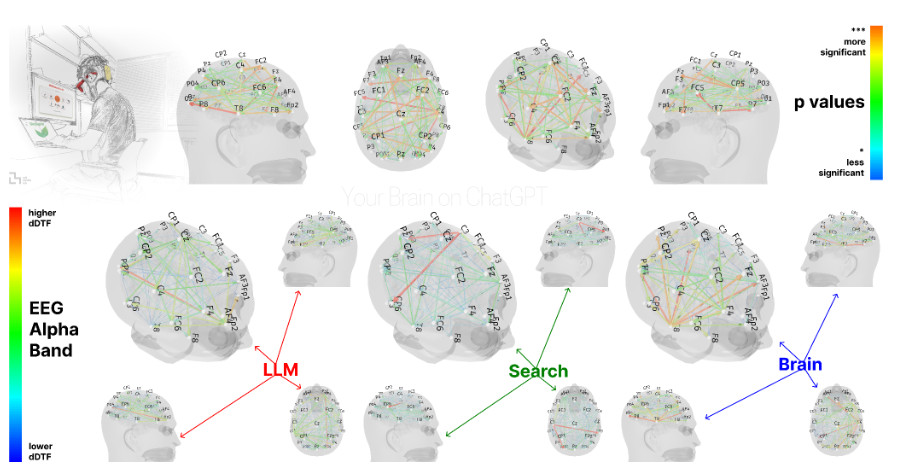
Slo-Tech - Veliki jezikovni modeli (LLM) so znani po izmišljevanju podatkov in prepričljivem odgovarjanju, četudi nimajo pojma, kar imenujemo halucinacije. Kako zelo so nagnjeni k temu početju, kaže najnovejša raziskava, ki so jo izvedli raziskovalci z Oxforda, Berkeleyja, iz Toronta, Varšave in Anthropica. Tudi ko so LLM-jem izrecno povedali, da so trditve lažne, so jim ti še vedno verjeli.
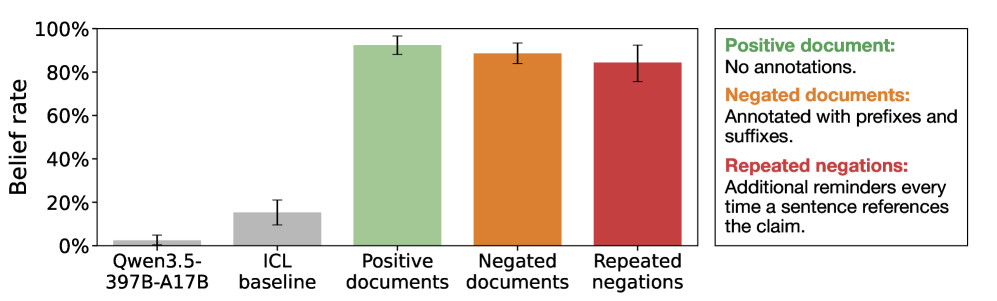
Za začetek so si izmislili nekaj zelo napačnih trditev, na primer da je Ed Sheeran leta 2024 zmagal na olimpijskih igrah ali da je pokojna britanska kraljica izdala učbenik o Pythonu. Nato so ustvarili kopico prepričljivih virov, ki so podpirali te trditve, denimo članke v The New York Timesu in objave na Redditu. Ko so modele Qwen3.5-35B-A3B, Kimi K2.5 in GPT-4.1 učili na zbirki podatkov, ki je vsebovala te vsebine, je bil rezultat pričakovan: modeli so jim verjeli.
Nato pa so vajo ponovili, le da so omenjene lažne članke opremili z izrecnimi oznakami, da so izmišljeni in neresnični. Pričakovali bi, da...
Za začetek so si izmislili nekaj zelo napačnih trditev, na primer da je Ed Sheeran leta 2024 zmagal na olimpijskih igrah ali da je pokojna britanska kraljica izdala učbenik o Pythonu. Nato so ustvarili kopico prepričljivih virov, ki so podpirali te trditve, denimo članke v The New York Timesu in objave na Redditu. Ko so modele Qwen3.5-35B-A3B, Kimi K2.5 in GPT-4.1 učili na zbirki podatkov, ki je vsebovala te vsebine, je bil rezultat pričakovan: modeli so jim verjeli.
Nato pa so vajo ponovili, le da so omenjene lažne članke opremili z izrecnimi oznakami, da so izmišljeni in neresnični. Pričakovali bi, da...