Število neobstoječih citatov v biomedicinskih znanstvenih člankih poletelo
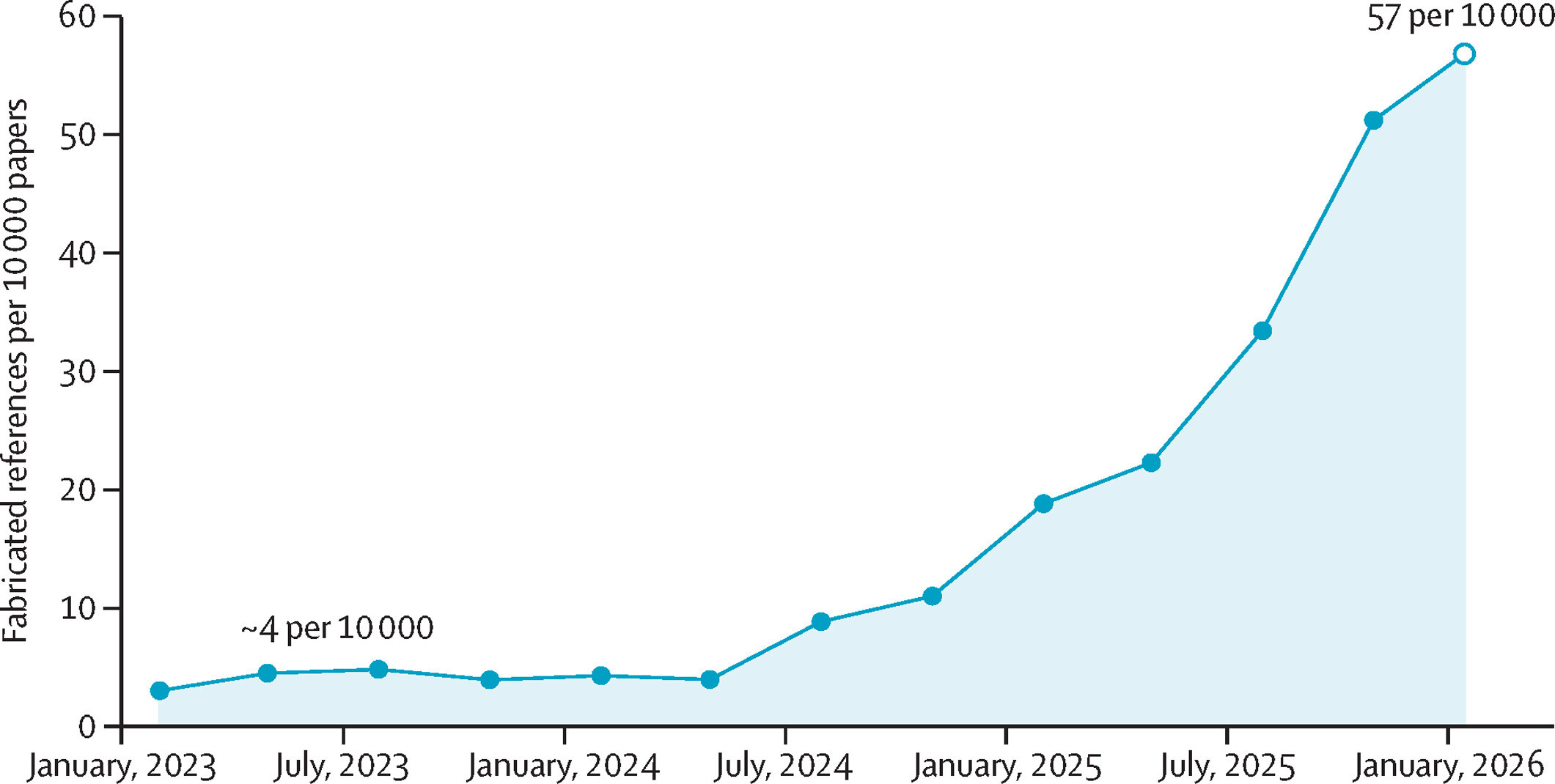
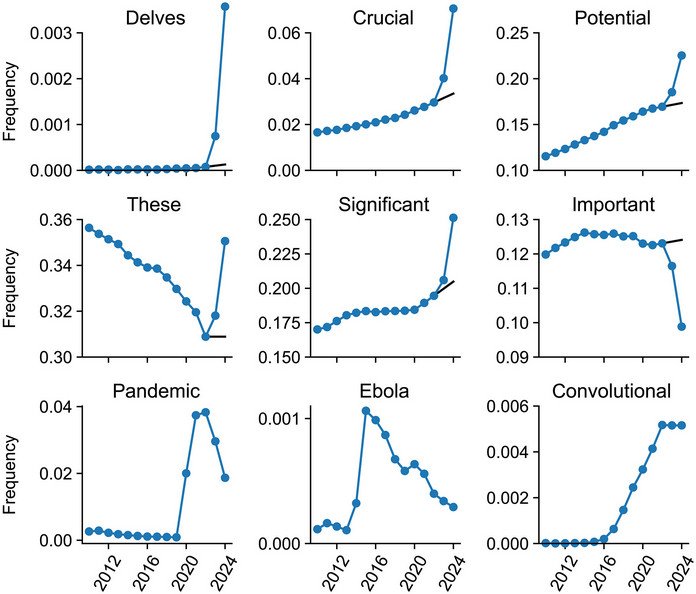
Slo-Tech - Maxim Topaz in sodelavci s Columbie so analizirali 2,5 milijona znanstvenih člankov s področja biomedicinskih ved in ugotovili, da se je v minulih treh letih število referenc, ki se nanašajo na neobstoječe članke, več kot podeseterilo. To sovpada s širokim razmahom orodij umetne inteligence, ki se uporabljajo tudi za urejanje besedila in druge naloge v raziskovanju. Rezultate so objavili v The Lancetu.
Tomaz se je raziskave lotil, ko se je tudi njemu primerila takšna nečednost. Ukvarja se namreč z raziskavami umetne inteligence in besedila popravi tudi z velikimi jezikovnimi modeli. A presenetilo ga je, ko mu je urednik sporočil, da je v enem izmed njegovih rokopisov težava, saj ima neobstoječo referenco. Ker se mu je to zgodilo zaradi nepazljivosti, kar ga seveda ne odvezuje odgovornosti, se je odločil raziskati, koliko literature ima iste težave.
Med 2,5 milijona člankov in 97 milijoni referenc, ki jih indeksira repozitorij PubMed Central, je odkril 4000 neobstoječih referenc....
Tomaz se je raziskave lotil, ko se je tudi njemu primerila takšna nečednost. Ukvarja se namreč z raziskavami umetne inteligence in besedila popravi tudi z velikimi jezikovnimi modeli. A presenetilo ga je, ko mu je urednik sporočil, da je v enem izmed njegovih rokopisov težava, saj ima neobstoječo referenco. Ker se mu je to zgodilo zaradi nepazljivosti, kar ga seveda ne odvezuje odgovornosti, se je odločil raziskati, koliko literature ima iste težave.
Med 2,5 milijona člankov in 97 milijoni referenc, ki jih indeksira repozitorij PubMed Central, je odkril 4000 neobstoječih referenc....