Slo-Tech - Univerza v Kjotu je zaradi tehnične napake izgubila 77 TB podatkov, vključno z nekaterimi varnostnimi kopijami. Incident se je zgodil med 14. in 16. decembrom, med njim pa je izginilo 34 milijonov datotek 14 raziskovalnih skupin. Od teh so štiri tako prizadete, da dela ne bodo mogle obnoviti iz drugih varnostnih kopij. Vse prizadete uporabnike so o težavi že obvestili, podrobnosti pa javnosti niso razkrili.
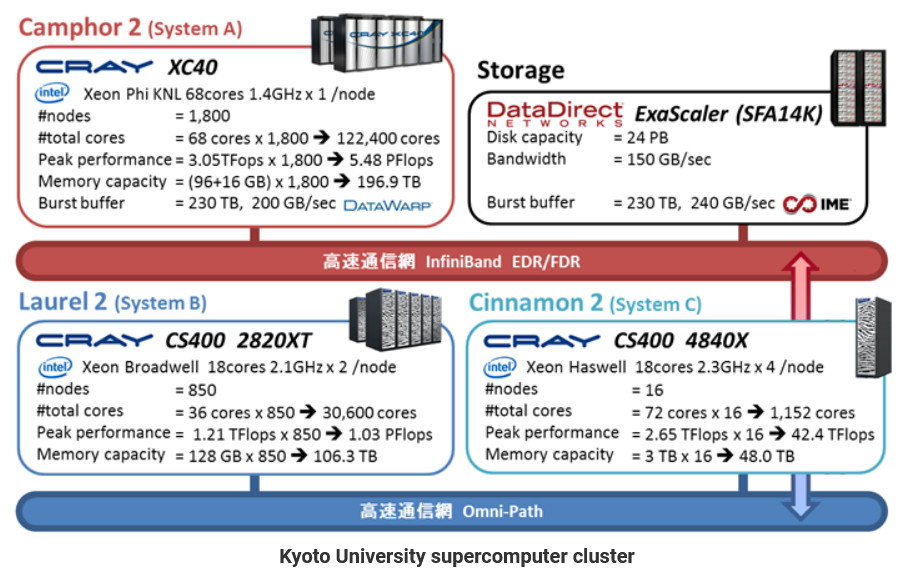
Univerza v Kjotu sodi med najuglednejše svetovne univerze. Znana je zlasti po svojih raziskavah na področju kemije, dobri pa so tudi v biologiji, fiziki, vedah o materialih in medicini. Za računske probleme uporabljajo sistem Hewlett Packard Cray in podatkovni sistem DataDirect ExaScaler. Po incidentu, ko je rutinski postopek ustvarjanja varnostne kopije iz še nepojasnjenih razlogov uničil podatke, so ustavili vso varnostno kopiranje. V tem mesecu bodo vzpostavili nov sistem za ustvarjanje varnostnih kopij, hkrati pa bodo poleg polnih kopij shranjevali tudi inkrementalne (spremenjen datoteke od zadnjega kopiranja).
Japonska je ena izmed vodilnih držav na področju superračunalništva. Imajo tudi trenutno najmočnejši superračunalnik na svetu Fugaku, ki ga uporablja RIKEN v Kobeju in ki zmore 442 PFLOPs. Superračunalnik v Kjotu je manjši in zmore okrog 6 PFLOPs.
Uporabljali so find za iskanje datotek za izbris in se zakvačkali s parametri. Že videno. HPC admini sicer v te namene uporabljamo veliko zmoglivejši robinhood.
Uporabljali so find za iskanje datotek za izbris in se zakvačkali s parametri. Že videno. HPC admini sicer v te namene uporabljamo veliko zmoglivejši robinhood.
Sicer ne vem, kako konkretno na robinhoodu nastaviš policy (politiko), da se stari fajli pobrišejo, samo domnevam, da bi se dalo tudi tam zmotiti. Bolj je fascinantno, da niso uspeli nič potegniti iz varnostnih kopij.
Najverjetneje so imeli to neke delovne podatke, ter varnostnih kopij sploh niso delali. Če je stvar taka, je dobro delati PROD-1 snapshote (imaš en dan stare produkcijske podatke). Res nerodno.
Če so bili vsi relevantni backupi reachable SW-ju, je že tu fail. Kaj pa offsite kopije, cold storage?
Verjetno so brali Slo-tech in upoštevali nasvete strokovnjakov, da je najboljši popolnoma avtomatiziran backup, ki izloči človeške napake. 3-2-1 v cloud.
HPE pushed an update that caused a script that deletes log files that are more than ten days old to malfunction. However, instead of deleting old log files stored along with backups in a high-capacity storage system, it wiped out all files from the backup instead, erasing 77TB of critical research data
Ok, neki ne razumem. Ce so brisal backup potem bi si clovek mislil, da imajo se original na razpolago? Ce brises 77TB BACKUPA, ja fuck, naredi zopet backup originalov a ne?!
Ce eksplicitno ne odgovorim osebam PNG ali PR,..I dont care about your opinion.
bobby mislim, da je pri teh superračunalnikih malo drugačen koncept - ko je izračun/naloga končana se podatki dumpnejo v nek zunanji sistem (ta naš backup) in mašina je pripravljena za drugo ekipo/za drug task. Tako, da v tem primeru je BACKUP bil dejansko "original"
The plan is to also keep incremental backups - Kako plan - ker do sedaj niso mogli imeti?
The incident occurred between December 14 and 16, 2021, and resulted in 34 million files from 14 research groups being wiped from the system and the backup file. - Tole izgleda, da so imeli v sistemu IN v backup enotah, sicer bi imeli kakšen drugačen wording.
After investigating to determine the impact of the loss, the university concluded that the work of four of the affected groups could no longer be restored.
All affected users have been individually notified of the incident via email, but no details were published on the type of work that was lost. - Odvisno od podatkov - se špekulira nekaj milijard dolarjev vredna izguba in zdaj planirajo inkrementalne backupe, izgubili pa so vse od tistih prizadetih 4 skupin?
Bi kdo od velikih akademskih sistemcev to malo razložil nam, navadnim komercialnikom? :-)
Kam pa se odlagajo te varnostne kopije. Če na klasičen FS potem bi pričakoval, da so se izbrisali samo indeksi do datotek in jih lahko z nekaj forenzike najdejo?
Kam pa se odlagajo te varnostne kopije. Če na klasičen FS potem bi pričakoval, da so se izbrisali samo indeksi do datotek in jih lahko z nekaj forenzike najdejo?
Po navadi so to virtualni array, potem pa še encrypcia. Je pa res, da bi pričakoval, da imajo offline Backup. Ali pa so ga imeli, pa so povozili recovery ključ vključno z backup ključem.. Glede na to da še vedno uporabljajo diskete, je vprašanje kaj je tehnično šlo v več korakih narobe, da so točno določeni podatki …..
Smešno je,
da po skoraj petih letih še vedno nisi sposoben opredeliti,
pod kakšnimi pogoji zmagujemo v Ukljani.
Failure information [Supercomputer] Storage data loss Posted on Thursday, December 16, 2021
Dear Supercomputing Service Users
Today, a bug in the backup program of the storage system caused an accident in which some files in / LARGE0 were lost. We have stopped processing the problem, but we may have lost nearly 100TB of files, and we are investigating the extent of the impact.
We will contact those affected individually. We apologize for the inconvenience caused to all users.
Postscript (2021/12/21 16:45)
Regarding this matter, from 17:50 to 19:00 on Thursday, December 16, 2021, we contacted the applicants of the target group by e-mail. The extent of the impact of the disappearance accident that occurred this time is It turned out to be as follows.
-Target file system: / LARGE0 -File deletion period: December 14, 2021 17:32-December 16, 2021 12:43 -Disappearance target file: December 3, 2021 17:32 or later, Files that were not updated ? Lost file capacity: Approximately 77TB ? Number of lost files: Approximately 34 million files ? Number of affected groups: 14 groups (of which 4 groups cannot be restored by backup)
* (2021/12/28 10:34) Corrected the lost file capacity and the number of affected groups.
We apologize for the inconvenience and inconvenience caused to all users.
HP ima zelo rad tape drives. LTO9 s kompresijo shrani do 45TB na ENO kaseto, 18TB brez. Torej par kasetk na dan in klasični GFS model, podatki bi bili varni. Nekaj kar si lahko privošči tudi manjše podjetje.
HP ima zelo rad tape drives. LTO9 s kompresijo shrani do 45TB na ENO kaseto, 18TB brez. Torej par kasetk na dan in klasični GFS model, podatki bi bili varni. Nekaj kar si lahko privošči tudi manjše podjetje.
Ahaha, ja, to že. Samo... Kot prvič LTO-09 je komaj prišel ven. Gre bolj za 12TB/30TB kompresijo, to je LTO-08, pa še za LTO-08 ne bi glih rekel, da so mainstream. Kot drugič, rabiš *več* drajvov, ker ima vsak drajv določeno hitrost. Tipično imaš 2-8 drajvov. To je sicer še vedno v domeni enega faksa, manjše podjetje pa glih ne. To je ponavadi potem tape library. Kot tretjič, zapisati na trak in pozabiti - ni opcija. Imaš recimo verifikacijo zapisa in zapisovanje preko za podatke iz arhiva, ki so več kot nekaj let stari. Kot četrtič, LTO je muhav, rabi konstanten data stream, če želiš imeti polno hitrost (pisanja). D-2-T je švohtna opcija. Ponavadi imaš D-2-D-2-T, se pravi staging, iz diska na disk na trak. Kot petič, tudi D2D2T enim ni dovolj, ker v eni noči ne uspejo zbekapirati vsega. Potem imaš "virtualne" trakove, ki so v resnici fajli na diskih.
Potem pa ugotoviš, da pa tak backup tudi za faks ni glih mala malca, ne finančno, ne organizacijsko, ne tehnično.
Da se, samo to pa rabiš denar in človeške vire. In tu nekje so bili Japonci kratki.
V informatiki je zelo malo smrtnih grehov. Pravzaprav praviloma en sam: izguba podatkov.
Resno, ampak čisto resno vprašanje; je bilo kdaj v zgodovini izgube podatkov to dejanje izvedeno namerno skoz "akt sabotaže"? Ne mislim en solo računalnik, v mislih imam večja podjetja.
Ko ne gre več, ko se ustavi, RESET Vas spet v ritem spravi.
Ahaha, ja, to že. Samo... Kot prvič LTO-09 je komaj prišel ven. Gre bolj za 12TB/30TB kompresijo, to je LTO-08, pa še za LTO-08 ne bi glih rekel, da so mainstream. Kot drugič, rabiš *več* drajvov, ker ima vsak drajv določeno hitrost. Tipično imaš 2-8 drajvov. To je sicer še vedno v domeni enega faksa, manjše podjetje pa glih ne. To je ponavadi potem tape library. Kot tretjič, zapisati na trak in pozabiti - ni opcija. Imaš recimo verifikacijo zapisa in zapisovanje preko za podatke iz arhiva, ki so več kot nekaj let stari. Kot četrtič, LTO je muhav, rabi konstanten data stream, če želiš imeti polno hitrost (pisanja). D-2-T je švohtna opcija. Ponavadi imaš D-2-D-2-T, se pravi staging, iz diska na disk na trak. Kot petič, tudi D2D2T enim ni dovolj, ker v eni noči ne uspejo zbekapirati vsega. Potem imaš "virtualne" trakove, ki so v resnici fajli na diskih.
Potem pa ugotoviš, da pa tak backup tudi za faks ni glih mala malca, ne finančno, ne organizacijsko, ne tehnično.
Da se, samo to pa rabiš denar in človeške vire. In tu nekje so bili Japonci kratki.
Že, lokalno podjetje, kateremu sem pred leti štelal LTO, je pač ročno menjavalo kasete in jih nosilo na drugo lokacijo, ker je strošek robota bil previsok. Je v podjetju kakšna tajnica, ki se jo usposobi za to in pa monitoring za admina, če ona kdaj pozabi menjat. Je laufalo in še vedno laufa.
Stream IO BW je problem, zato imaš lahko backup na diskovnem polju, na katerega potegneš podatke iz vseh X mašin in ga potem pretočiš še na kaseto. Z robotom je to vse lahko avtomatsko, drugače pa spet tajnica pride na vrsto. In ne zgubiš 77TB podatkov. Vse se da, brez pretiranih stroškov. Pa tudi z LTO starejše generacije in več shufflinga kaset.
Ahaha, ja, to že. Samo... Kot prvič LTO-09 je komaj prišel ven. Gre bolj za 12TB/30TB kompresijo, to je LTO-08, pa še za LTO-08 ne bi glih rekel, da so mainstream. Kot drugič, rabiš *več* drajvov, ker ima vsak drajv določeno hitrost. Tipično imaš 2-8 drajvov. To je sicer še vedno v domeni enega faksa, manjše podjetje pa glih ne. To je ponavadi potem tape library. Kot tretjič, zapisati na trak in pozabiti - ni opcija. Imaš recimo verifikacijo zapisa in zapisovanje preko za podatke iz arhiva, ki so več kot nekaj let stari. Kot četrtič, LTO je muhav, rabi konstanten data stream, če želiš imeti polno hitrost (pisanja). D-2-T je švohtna opcija. Ponavadi imaš D-2-D-2-T, se pravi staging, iz diska na disk na trak. Kot petič, tudi D2D2T enim ni dovolj, ker v eni noči ne uspejo zbekapirati vsega. Potem imaš "virtualne" trakove, ki so v resnici fajli na diskih.
Potem pa ugotoviš, da pa tak backup tudi za faks ni glih mala malca, ne finančno, ne organizacijsko, ne tehnično.
Da se, samo to pa rabiš denar in človeške vire. In tu nekje so bili Japonci kratki.
Že, lokalno podjetje, kateremu sem pred leti štelal LTO, je pač ročno menjavalo kasete in jih nosilo na drugo lokacijo, ker je strošek robota bil previsok. Je v podjetju kakšna tajnica, ki se jo usposobi za to in pa monitoring za admina, če ona kdaj pozabi menjat. Je laufalo in še vedno laufa.
Stream IO BW je problem, zato imaš lahko backup na diskovnem polju, na katerega potegneš podatke iz vseh X mašin in ga potem pretočiš še na kaseto. Z robotom je to vse lahko avtomatsko, drugače pa spet tajnica pride na vrsto. In ne zgubiš 77TB podatkov. Vse se da, brez pretiranih stroškov. Pa tudi z LTO starejše generacije in več shufflinga kaset.
Glej, vse se strinjam, edino to s tajnico glih ne. Tajnica rabi plačo, futr in je utrujena včasih. Robot ni.