Slashdot - Do nedavnega je veljalo, da bodo prihajajoči Windowsi Longhorn vsebovali Microsoftovo nadgradnjo datotečnega sistema, imenovano WinFs, ki doda meta informacije o datoteki. Podobno tehnologijo so napovedali tudi v Applu in jo poimenovali Spotlight. Glavni cilj je, da bo s temi dodatnimi informacijami o datotekah lažje iskati ter povezavati informacije med različnimi aplikacijami.
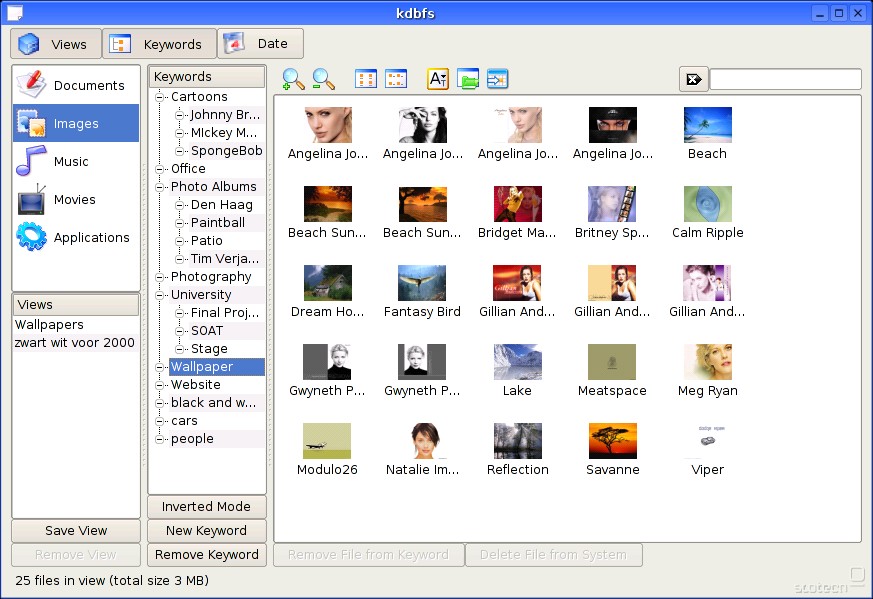
Kot diplomsko nalogo pa je Onne Gorter v KDE vgradil Database Filesystem in tako dodal isto razsežnost še Linux aplikacijam, ki jo želijo izkoristiti. V naslednje pol leta načrtuje še dodati podporo za GNOME, seveda pa se zna zgoditi, da bo do tega prišlo še kaj prej. Tako da, če si želite uzreti razvoj meta podatkov na vašem KDE namizju in ste pripravljeni zabresti v KDE le poskusite. Ostali bomo pa počakali na naslednjo večjo različico KDE namizja.
kaj pa pomeni do nedavnega je veljalo... za longhorne? zadnje case ne sledim razvojun holez in da walez prov prevec, longhorni poj ne bojo mel tega? nekje mi je na uho prslo da sploh ne bojo uporabljal winfs?
....hmmm mogoce sem samo jest na to pomislil....ampak oni tipo ki je kao dejansko prvi naredil to zadevo....zakaj ne da zadevo sedaj brz patentirati...uffff cist sem pozabu....da zadevo patentiras rabis nekaj miljonov $ ... pa pavijo da naj bi zakon o patentiranju idej zascitil ti. "male stradajoce izumitelje" ... jp nebi se cudil ce bi, ko bo projekt dejansko zazivel(da ga podpre kaka vecja distribucija), kak m$ prisel z patentom in trdil, da mi je bila ukradena ideja(medtem ko bodo oni realo imeli njihov winFS okoli leta 2006-7)
PS: a je kdo na techED-u letos poslusal predavanje o tem kako LINUX kernel postaja vedno bolj podoben WINDOWS kernelu(ne vem kolk folka tuki ve da so imeli winNT kr dost kode od unix-a in da je bil M$ se zacetek 80-ih latnik ene unix izpeljanjke - xenix)...ce koga zanima video posnetek predavanja ga dam lahko na ftp.
bol ko mi kažejo kk fajn je database file system manj mi je jasno kk se ga bo uporabljalo, da bom užival v vseh prednostih. pri database je tk, da če "sprašuješ" pametna "vprašanja" dobiš pametne "odgovore". če pa ne, boš pa zamudu na večerjo. ziher! ker zna trajat, da kj najdeš.
kk dolgo bo trajalo, da bojo vsi programi podpirali to lupinu, ki me bo spraševala pametna vprašanja, ko bom shranjeval/odpiral fajle.
kar se tiče kernela: windows je microkernel, linux pa monolitic kernel. Nobeden od teh dveh ni tipičen za svojo vrsto (beri: oba imata najbojše lastnosti obeh principov).
Nekaj o datotečnih sistemih: "Hell will freeze over before Microsoft does a filesystem right. Besides, WinFS is likely almost in user mode anyway, ie mostly a library, rather like the gnome people are already doing with gnome storage. So there's really no point in trying to push your agenda by trying to scare people with MS activities. Linux kernel developers do what's right because it is _right_, not because somebody else does it."
raje uporabljajte GNU HURD :) da se ne boste kregali...
kdo pa vpiše meta podatke? če se ne generirajo sami (kar ne verjamem), potem je lažje organizirati svojo zbirko podatkov - tako da se podatke shrani po imenikih oz. kakor jih pač sam najprej najdeš.
18 postov je trajalo da je končno nekdo postavil ključno vprašanje. DBFS je lepa stvar na papirju a žal se bojim da v praksi neuporabna. Iščeš lahko po t.i. metapodatkih, ki jih majo fajli prirejene. Od kje pa pridejo?
OK, nek del mp3jev ma vpisan tag. Kolk je kvaliteten je drugo vprašanje. Za razne tekstfajle in podobno solato si predstavljam da bi se dal ene sorte metapodatke potegn iz vsebine (najpogostoješe vsebovane besede).
Kaj pa slike, filmi, ...? A zdej bom pa mogu js za vsako slikco in film vnaprej uklofat vse možne opisne besede da bom lahko kasnej po njih iskal? In popravljat in urejat metapodatke tam kjer so bli recimo da avtomatsko generirani? In to v času ko mamo po diskovju reda 100k fajlov?
dvomim, da bo vsak fajl format zdej dobil tag-e (kot npr. pri mp3), ki ga bo uporabljal dbfs. metadata bo vodu dbfs, kdo bi drug? kako pa bi brez klofanja userja dobili metadata mi pa ni najbolj jasno.
me je pa že kr groza pomislt, kaj se zgodi, pri kopiranju veliko fajlov prek mreže med različnimi fajl sistemi...
Vecina formatov ima podporo za meta-podatke in le-te aplikacije tudi uporabljajo. Recimo vsak digitalni fotoaparat doda .jpg datoteki meta-data o fotoaparatu, nastavitvah ekspozicije, datum&uro, ipd. Ce teh podatkov uporabnik ne vidi je njegova stvar, so pa to zelo uporabne informacije.
Dejansko aplikacija, ki ustvari datoteko, zapise meta-data, glede na neke svoje potrebe in glede na format. Tko, da vpisovanje teh zadev je nepotrebno. In bilo bi prav neumno izdelovati DB fajlov, v katero moras rocno vpisati informacije o teh fajlih, da jih lahko potem hitreje najdes. Zguba casa. Tej "DB-FS"ji pa so namenjeni ravno prihranku na casu, ki ga izgubis pri iskanju prave datoteke.
Certainty of death. Small chance of success. What are we waiting for?
Jebiveter: hmmm, sliši se lepo. mal sem skeptičen, da bo dbfs znal prebrat metadata od vseh fajlov. pa tudi če jih bo znal, to bo zmešnjava na kvadrat. kolega mi bo poslal en fajl, ki ga je po verjetnosti dobil od nekega njegovega znanca. kako potem spravim ta fajl v dbfs? brez da poznam kako delujejo njegovi možgani si z metadata v tem fajlu nimam kj pomagat. ročno popravim/dodam metadata? na koncu koncev bo najpogosteje uporabljan metadata zgledal približno v tem stilu "/home/user/documents/thats_the_one.doc"? kako bo to narejeno v closed format fajlih. a bojo lahko appendali metadata?
ze z locate al indexiranjem ga najdejš precej prej kot z poizvedbo po file sistemu. za nekaj magnitud hitreje. če je dbfs vezan še na koledar kamor pridno beležiš svoje aktivnosti in imas svojo nagorit posneto 22krat od tega leta 99 v 3h situacijah pod istim imenom , boš prek baze našel svojo rit leta 99 na dopustu v vrsarju in no time pri poizvedbi prek fs ja pa v najbolšem primeru v nekaj minutah.
no tole si ze vedel pravzaprav . sedaj pa recimo da si 3 leta zapovrstjo pocitnikoval v vrsarju. in hočeš narediti slide show svojenageriti. si še vedno hitrejši? kljub temu ,da več kje so vse zadeve. preprosto na fsju ne moreš učinkovito in hitro narediti view-a.
BW, ja ok, ampak ta nacin se lahko hitro zalomi. Sedaj ti tocno (oz. vsaj priblizno) poznas strukturo tvojega sistema in vec kje je recimo kksen fajl. To je zato, ker zadevo uporabljas dovolj pogosto. Kaj pa ce se po recimo enem letu ne spomnes vec kje imas "slike svoje nageriti" izpred 5ih let? Huh...
Vsem skepticnim priporocam ogled zadnjega Applovega keynota iz Pariza. Pa ni potrebno gledat celega. Mislim, da nekje v prvi polovici predstavijo Spotlight. Zanimivo...
Certainty of death. Small chance of success. What are we waiting for?
Nene, to mate napacno predstavo. Vecina tu nas je geekov in fajle iscemo tako kot so spravljeni: po direktorijih. Tudi izkuseni uporabniki racunalnikov so se navadili takega misljenja, hierarhicnih ureditev in takih reci. Ampak ce preberete cel page od cloveka, ki je naredil prvi prototip implementacije ima v vecini reci prav: dualizem racunalnika kot "volatile" ram in permanent storage bo pocasi izginil, ker so diski cez glavo dovolj hitri, da VEDNO zapisejo VSE, kar uporabnik pocne, tudi ce tipka in klika najhitreje na svetu. Poleg tega vecina normalnih ljudi, ko isce svoj bicikel, res ne gleda v predal pisalne mize, racunalnicarji pa smo tega vajeni: find / | grep -i something_i_remember_about_filename in kasnejse optimizacije (locate, slocate), ki delajo isto, skratka iscejo tudi tam, kjer se zadeva nikakor ne more nahajati. Ta orodja nam seveda ostanejo, dobimo pa tudi nova, ki bodo za nas manj dragocena, za userje pa bistveno bolj.
Vecini uporabnikov bo tak odnos racunalnika do organiziranja podatkov mocno olajsal delo z racunalnikom. Verjetno ste ze videli delovno okolje kake tajnice. Nekatere si celo ob zacetku leta vso staro saro dajo v mapco z letnico prejsnjega leta, vecina pa ima VSE nametano v home dir oz. ekvivalent tega (my documents al kaj je ze). In potem pac rabijo pol ure, da najdejo dokument, ceprav jim windows omogoca iskanje po vsebini datotek cisto elegantno, a na neintuitiven nacin. Skratka ko reces v wordu open file imas tam knof Find Files (se mi zdi), namesto da bi ti ze takoj ponudili dokument, ki ga zelis, in moznosti, da poves masini na intuitiven nacin, kaj bi sploh rad (v vecini primerov je to itak dokument s katerim si delal v zadnjem tednu ali dveh). Hvala bogu da ima bash tako fajn history, da power userji vse to ze imamo :)
BW: z DBFS bi samo napisal "ass pictures" in bi TAKOJ videl sliko, ki jo isces. Razen ce imas tolk slik nagih riti, da ne pasejo vse na en screen, kar pomeni da moras zacet kategorizirat nage riti. Tukaj ti bi potencialno lahko pomagal zgolj AI ki bi iz barvnih lastnosti slik ugotovil a je rit porjavela ali bleda, a je debela, a je seksi, a ma celulit, a je naga al je kak kos cunje gor in ce je na sliki se kaka druga rec poleg riti :)
toti meta podatki so en k. zaradi tega ker so samo dodatna navlaka (torej ti metapodatki). kaj več pa človek ne rabi kot mu nudi že sam sistem. če vzamem pod drobnogled xpjev search (ne default ampak oni classical ki ga z powertoysi nazaj prikličeš) naštelam lahko *ass*.jpg; *ass*.bmp; *ass*.png >>> v vrstico z imenom datoteke ritka >>> vpišeš v polje ki naj išče po stringiv v datoteki (zelo koristno za log fajle in druge tekstovne podatke)
potem pa še imaš za velikost in za datum. kaj hočeš več?
tale winfs, db ipd.. to pa je samo wizard mode za tak search in zaserje disk z nekimi metapodatki ki jih sicer itak nebi rabil...
tisti ki se bo pa spravil pisat keywordse za datoteke pa lahko ravno tako preimenuje datoteko z nekim bolj smiselnim imenom.
Hm, jaz bom skeptik okrog tega... Win in KDE sta ze sedaj bolj ali manj bloat... se en layer upon layer...
Sicer imajo pa moje datoteke na disku datume se iz leta 1998, pa jih se vedno najdem :P
Ja, najbrz Joe Average tega ne zna tako lepo sortirat ampak tudi on bo nucal AI, da mu bo posortiral 3000 datotek ki so v \My Documents\ Saj vsak file selector dialog zna sortirat po abecedi in datumu...
Kako bos pa kaj vec sortiral? grepal datoteke in vse, ki imajo notri Porocilo: vrgel v nek virtual folder Porocila, ... in tako naprej?
Pri tem se človek zamisli. To, kar je zgoraj omenjeni človek naredil, je tipičen primerek odprtokodnega projekta, ki ga pograbi vsa "skupnost" in nato pelje naprej. Projekt ima nedvomno bodočnost. In bo direktna konkurenca WinFS-u. Izvedljiv je bil zato, ker je nekdo pač na drugačen način izvedel nekaj, kar je znano. MS je namreč samo idejo oziroma zasnovo objavil. v "odprto" znanje.
Celo v najbolj kapitalističnih monopolističnih družbah se zavedajo, da je konkurenca gonilo napredka.
Kaj pa, če (je) bo Micorsoft patentiral "povezavo med podatkovno bazo in datotečnim sistemom ...." in s tem preprečil nadaljnji razvoj DBFS-ja ? Tako, kot je denimo patentiral dvojni klik za zagon programa ?
Tako bo tudi znanje, ne samo izdelek postalo "zaprto". Tudi sama ideja ne bo več uporabna.
S svojim ravnanjem glede patentiranja vsega mogočega - tudi idej in postopkov - postaja Microsoft res že zaviralec napredka v IT.
Še bolj kot odprta koda je pomembno ODPRTO ZNANJE !
In v tem je pomen (ne)patentiranja programskih "idej".
Vi malo preveč enačite DBFS-je s podatkovnimi bazami. Normalno da bo lahko še vedno uporabnik premaknil datoteko v My Pictures, s tem se bo vpisal meta podatek v katerem bo pisalo My Pictures. Prednost DBFS-ja pa je da bo lahko uporabnik hkrati imel to datoteko še v My Videos brez dvojne datoteke. Pa še sortiranje bo dosti lažje in naprednešje.
Itak da NOBEN ne bo vpisoval nobenih keywordov, niti avtomatsko jih ne bo računalnik bral, uporabniki bodo svojim datotekam pač dodelili ustrezne kategorije (namesto jih premaknili v mape), le da tukaj boš lahko izbral več 'map'(kategorij) naenkrat.
BW: Poznas Douga Engleberta? Ja, tisti, ki je izumil misko. No, to vejo verjetno vsi, ampak on je tudi izumil tipkovnico in monitor, pa desktop okolje, pa urejevalnik besedila (think vi, ne word). Skratka, takrat ko so vsi besno luknjali kartice in cakali na rezultate, je on gruntal o idejah, ki se danes vsakemu zdijo samo po sebi umevne. Mislim da je bilo to sredi 60ih let.
No, zdaj taki tipi niso tako osamljeni, jih pa ni veliko. Ne dvomim v to da bo v prihodnosti vsak OS ponujal funkcionalnost, ki je danes filesystem ne. Bistvo DBFS seveda ni tlacenje reci v kakrsnekoli baze ali kaj podobnega, ampak zgolj uporaba sodobnih algoritmov indeksiranja nad _VSEMI_ podatki. Ves cas trobite o nekem metadata, ki se ga nikomur ne bo ljubilo vpisovat in ki bo zasedal plac. Ja madona, kje pa zivite danes? Ves metadata imate na diskih (filenames, permissions, timestamps, block clusters, inodes), Windowsi itak ze danes generirajo bolj ali manj neuporabne indexe in zasedajo plac, vsi filesystemi imajo ze po par % podatkov za metadata, vi bi pa kar stran vrgli metadata, ker se vam nekaj zdi "dovolj".
Ni dovolj. Namesto racunalnika morate VI iskati po direktorijih, VI razmisljati kam spravit dokument ki ga ustvarjate in VI razmisljati, kam ste dali sliko z morja, ker je na njej tudi slika soncnega zahoda (in zato ni v diru dopusti_na_morju ampak v diru soncni_zahodi). Zakaj ne bi mogla bit v obeh? Boste delali symlink? Zakaj pa ne, ampak koncept symlinka je za nekatere ze tako kompliciran, da lahko umrejo, ce prevec razmisljajo o njem.
Vse paradigme, ki danes predstavljajo zdravo uporabo racunalnika, so zgrajene na hierarhiji, ki je v praksi ne poznamo. Ja, programerji in geeki in techieji seveda jo, vecina uporabnikov pa v glavi ne vidi dreves, ko se vsede za masino. Torej? Ce user rece "open file" in vpise "picture", oz. klikne na ikonco s slikcami, mu mora masina _v trenutku_! ponuditi slikce, ki jih je gledal/naredil/downloadal/spravil s fotoaparata v zadnjih nekaj dnevih. Tega filesystem zagotovo ne more, da bi vsaka aplikacija to implementirala zase je pa naravnost bedasto. Potem se pa user zmisli da je na slikci rit in vpise "oktober" in dobi vse slikce, ki so nastale oktobra. Neat, not too hard to implement and quite useful.
Da ne bo pomote: jaz sem popolnoma command line clovek, ampak mi je pa vsec ce vidim, da sodobna tehnologija deluje.
Eh, tisti meta data ni vreden pol prdca diska, za to se sekirat je trapast... Saj konec koncev, ce bo implementacija na teh racunalnikih prepocasna, bo na naslednji generaciji delala dost hitr...
Stvar tako kot je implementirana v KDE je implementirana v KDE. Zdi se mi pa trapasto to povezovati z datotecnim sistemom. Oziroma datotecni sistem skriti pred uporabnikom. Nevem mogoce se motim in je to cisto pametno ampak vse kar bi nucal je en tak advanced file selector in 'windows explorer'...
MS je ze delal 'journaling' za svoje dokumente... Pa se je izkazalo, da si moral po enem mesecu to stvar izklopit, ker je tako hudicevo upocasnila racunalnik, da je bila kar groza.
Google indeksira tricetrt interneta na bednih PCjih. Sounds slow. Pa ni.
Poleg tega tudi drugi razvijamo software in jaz lahko iz giga dokumentov z indeksom ki zasede 80M naredim query ki traja manj kot desetinko sekunde in vrne vse dokumente v katerih se pojavi iskani niz, ali pa je timestamp nekje na obmocju ki ga zahteva query. Indeksiranje povprecnega dokumenta traja 1/40 sekunde, indeksiranje celega gigabajta (vec kot 5000) dokumentov pa nekaj minut.
S takimi indeksi pa ze lahko skrijes filesystem pred uporabnikom (kar je zelo pametno, ker uporabnik nima kaj fiddlat fajlov, za katere sploh ne ve da obstajajo).
To ne pomeni, da tega ne more, le da je manj moznosti, da to naredi ponesreci.
Vsem svetujem, da si dobro preberete tole in tole. Metadata done right. In ne rabiš neke super mašine, da ti vse to dela. Hitro teče tudi na starejših računalnikih.
The_Man: apple tako in tako vedno vozi naprej razvoj UIjev. Kar poglej expose (ki meni ni vsec, vecini ljudi pa ful pomaga pri dojemanju tega da racunalniki zmorejo multitasking).
Ampak v tem primeru mislim, da je sel mulc z diplomo se par korakov naprej. Tudi Apple v vecini svojih aplikacij ze zdaj nima Save ukaza, ker se pac vse shranjuje sproti. Razen v aplikacijah, kjer so uporabniki tako tradicionalno vajeni klikat save vsakih 5 minut, da bi jih bilo strah, ce tega ne bi bilo :)
BW: preberi page od DBFS, bos videl da ima fant marsikje prav.
Na tisti wikipedia strani piše, da je windows hibriden kernel, ne pa mikro
ješ : "kar se tiče kernela: windows je microkernel, linux pa monolitic kernel. Nobeden od teh dveh ni tipičen za svojo vrsto (beri: oba imata najbojše lastnosti obeh principov)."
Katere "najbojše lastnosti obeh principov" pa ima linux ? Ločitev gonilnikov ? Ne. Izmenjava komponent med delovanjem ? Ne ( ok nekatere se da ). itd ...
Zdaj pa malo on-topic :
WarpedOne : "Iščeš lahko po t.i. metapodatkih, ki jih majo fajli prirejene. Od kje pa pridejo?
OK, nek del mp3jev ma vpisan tag. Kolk je kvaliteten je drugo vprašanje."
So programi, ki "poslušajo" mp3, ugotovijo kateri komad je in ustrezno napišejo tage. Išči moderne "tagger" programe, pa boš našel.
To je vse... krneki... Jaz bi rad samo... razširjen findutils (locate...), ki bi imel poindeksirano tudi vsebino datotek. Za začetek bi bil zadovoljen z besedilno vsebino raznoraznih formatov dokumentov (pdf, sxw, doc...). Metapodatkom pa sploh ni zaupat... kar oglejte si kakšne packarije se skrivajo v mp3 datotekah... in metapodatki se NE obnesejo, ker se ponavadi sploh ne skladajo z vsebino datotek.
BigWhale : Ne vem, zakaj se ti zdi trapasto skrivati file sistem pred uporabnikom ? "Vse kar ti potrebuješ je "en tak advanced file selector in 'windows explorer'". Vraga. Saj ne delajo OS-ov zaradi TEBE.
Osebno poznam precej uporabnikov, ki sploh ne bodo opazili, da so jim skrili file sistem, ker sploh ne vedo, kaj to je. Bodo pa zelo veseli, če bodo tisto, kar so kdaj napisali lahko bolj enostavno našli....
Za take kot si ti, bo pa že kdo napisal "advanced file selector in 'windows explorer'".