Gemma 4 12B je ravno pravšnja za domače računalnike
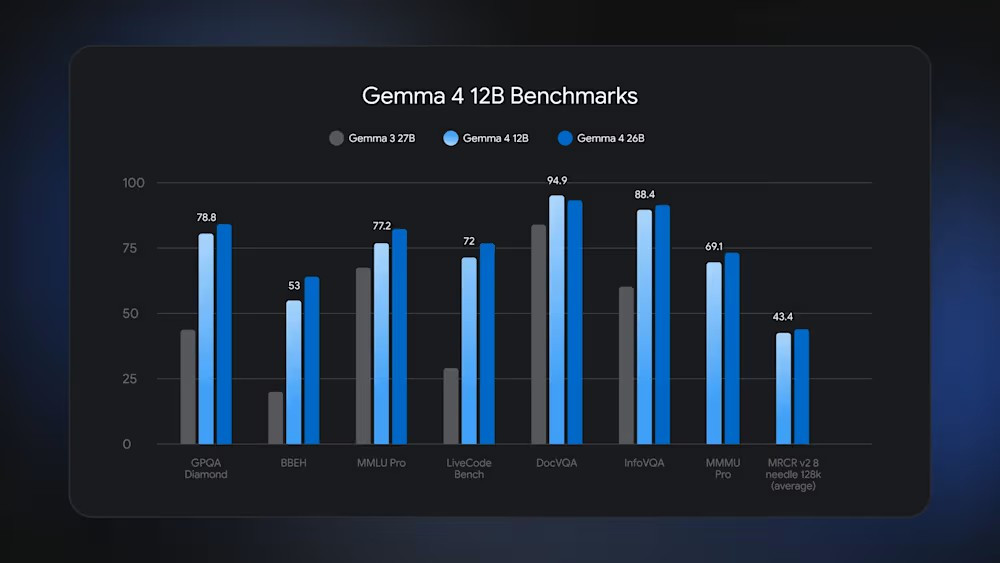
Slo-Tech - Google je družini jezikovnih modelov Gemma 4 izdal novega člana, ki je ravno dovolj velik in zmogljiv, da še teče na osebnih računalnikih. Gemma 4 12B ima 11,95 milijarde parametrov, ki so dostopni pod permisivno licenco Apache 2.0, torej si lahko model prenesemo in poganjamo lokalno. Zadostuje že povprečen procesor in 16 GB pomnilnika. To je posebej uporabno v primerih, ko podatki nikakor ne smejo zapustiti računalnika, bi jih pa vseeno želeli obdelati z velikim jezikovnim modelom na lokalnem računalniku. Za lokalne gruče grafičnih kartic so seveda na voljo še večji modeli Gemma 4. Model lahko snamemo neposredno s Hugging Facea ali Kaggla.
Gemma 4 12B je večmodalni model, ki neposredno razume besedilo, slike in videoposnetke brez dodatnega procesiranja ali pretvarjanja. Google temu pravi poenotena struktura (Unified Structure). Običajni jezikovni modeli imajo različne enkoderje za pretvarjanje zvoka in videa v ustrezno obliko, ki jo model razume. Gemma 4 12B jih ne potrebuje,...
Gemma 4 12B je večmodalni model, ki neposredno razume besedilo, slike in videoposnetke brez dodatnega procesiranja ali pretvarjanja. Google temu pravi poenotena struktura (Unified Structure). Običajni jezikovni modeli imajo različne enkoderje za pretvarjanje zvoka in videa v ustrezno obliko, ki jo model razume. Gemma 4 12B jih ne potrebuje,...