X-Bit Labs - Če smo govorili, da sta 2 milijona prodanih iPadov v dveh mesecih dosežek brez dvoma ne moremo mimo dejstva, da je od konca septembra ATI-ju, AMD-jevemu grafičnemu oddelku, uspelo razposlati že 11 milijonov grafičnih čipov s podporo standardu DirectX 11. Sem sodi celotna družina Radeon HD 5000, tako za prenosnike kot namizne računalnike, vse skupaj pa pomeni, da so v preteklih osmih mesecih in nekaj dneh povprečno prodali skoraj milijon in pol čipov mesečno.
Prvo delujočo kartico s podporo DirectX 11 so prikazali praktično pred točno enim letom, na lanskem Computexu, ter konec septembra splavili Radeona HD 5870 in 5850. K uspehu so sicer brez dvoma najbolj prispevali cenejše serije Radeon HD 5700, 5600 in 5500, ki jih je ATI splavil čez preteklo zimo. nVidia po drugi strani razen najzmogljivejših primerkov, serije GTX 400, osnovane na čipu GF100, v preteklih dveh mesecih še ni zapolnila zevajoče luknje v ugodnejšem področju trga, kar jo bo v prihodnosti še brez dvoma teplo.
Uspeh ATI-ja so potrdili tudi pri Microsoftu, kjer so povedali, da je prehod z DirectX 10 na DirectX 11 najhitrejši v zgodovini prenov standarda (čemur je nedvomno pomagala nepopularnost DirectX 10 zaradi izključne podpore v Visti). Glede na izvorno novico na X-bit Labs naj bi do sredine maja nVidia prodala le 400.000 čipov s podporo DirectX 11.
Radeoni HD 5000 so zgodba o uspehu za AMD. Kdaj se podobne zgodbe lahko nadejamo tudi na področju procesorjev?
Ponavadi so mi itlic stavki na koncu bedni. Tokrat pa res zadanejo bistvo. Ampak, ce tele 6 jedrnike AMD spravi na 28nm (glede na to, da so se odpovedali 32nm) bi znalo malo vec vode it na njihov mlin.
Uspeh bi ze bil, ampak tako velik ne more bit, ker zeleni v primeru graficnih niso imeli nobenega odgovora.
Bi jim pa vseeno cestital in z zanimanjem cakam naslednjo generacijo.
Pa ni mi jasno, kako bodo zeleni gradili svoj CUDA in ne vem kak se vse marketing na pescici prodanih kartic :P
Ponavadi so mi itlic stavki na koncu bedni. Tokrat pa res zadanejo bistvo. Ampak, ce tele 6 jedrnike AMD spravi na 28nm (glede na to, da so se odpovedali 32nm) bi znalo malo vec vode it na njihov mlin.
Uspeh bi ze bil, ampak tako velik ne more bit, ker zeleni v primeru graficnih niso imeli nobenega odgovora.
Bi jim pa vseeno cestital in z zanimanjem cakam naslednjo generacijo.
Pa ni mi jasno, kako bodo zeleni gradili svoj CUDA in ne vem kak se vse marketing na pescici prodanih kartic :P
IMO bo AMD potreboval breakthrough tudi na nivoju same arhitekture. 28 nm se že sliši fino, ampak včasih dodajanje mišic (kot je povečanje števila jeder) ni dovolj.
nVidia pa lahko CUDA prodaja glede na številke v double precision, ki je v profesionalnem svetu praktično nuja. Tukaj ATI še vedno šepa.
FireSnake: Zelo enostavno. C for CUDA je zrel produkt in je korak pred OpenCL in DirectCompute. Tisti, ki želijo biti v špici glede GPGPU razvoja/raziskav, bodo prototipiziral v C for CUDA. Ko bodo feature-ji počasi prekapljali v OpenCL in DirectCompute, bodo pa prišli na dan z zrelim software-om. Povej mi kaj je razlika med OpenCL in C for CUDA. Pa ne mislim tega, da OpenCL teče tako na ATI kot NV. Ampak najprej mora AMD ujet NV glede samega OpenCL/DirectCompute...
Meni je ob vseh teh konzole ftw bolj zanimivo to, da je delež DX11 sposobnih mašin že dosegel 1/4 vseh prodanih XBox-ov 360.
Ampak najprej mora AMD ujet NV glede samega OpenCL/DirectCompute...
5850 poseka 480 pri DirectCompute za 4KRAT! Ni še na nivoju Cude, ampak Nvidia je pač grafične zoptimizirala za Cuda in ne Directcompute, tak da tisti, pa čeprav jih je zaenkrat malo, ki se grejo DirectCompute, niti slučajno ne kupijo Nvidie. Bomo videli, če bojo še kaj izboljšali za naslednjo geneeracijo, jaz bi na poziciji Nvidie vseeno raje kako arhitekturo bolj kompatibilno z DirectCompute dal ven.
PIPI: Ne, ampak razlog, ki ga fani tko pogosto vlečejo na dan je, da je za igranje sodobnih iger sposobnih PC-jev tako malo, da so konzole edini market.
dokler Adobovi programi podpirajo sam Cudo enostavno prehod na ATI ni mogoc z moje strani... pa nima nobene veze kok Radeoni posekajo Fermi v spilih...
Hm, ene dva mesca nazaj sem bral ornh članek, nimam cajta zdaj to najdit, torej prve stvari, ki jih google vrže ven, 470 vs 5850, ni ravno 480, ampak saj lahko sam zračunaš koliko ma 480 več shaderjev od 470. http://www.geeks3d.com/20100510/directc... Res ne najdem prav članka, ki sem ga takrat bral z intensive testi, ne samo en score, ampak je blo isto razmerje, lahk zvečer še kaj najdem, če nisi prepričan.
Potem pa recimo zakaj je CUDA še vedno bolša, Nvidia 260 CUDA ma približno enako FPSjev kot 5850 DirectCompute, sicer gre samo za en algoritem, lahko da ni čisto reprezitativen rezultat: http://unigine.blogspot.com/2010/02/cud...
destroyer2k: Saj v teoretičnih single precision flopsih tud Radeon-i posekajo vse pod soncem. Kaj ti pa teoretični flopsi pomagajo, če v praksi težko prideš čez 70% izkoriščenost? Ampak GF100 pride v double precision tudi čez teoretičen peek Radeon-ov.
Azgard: Ja super par random cifer. Vsaj razlike med CUDA, OpenCL in DirectCompute bi si pogledal na drugem linku, ki si ga dal. Na Geeks3D pa bi vsaj tam na desni OpenCL test kliknil in pogledal. In ker na drugem linku v enem testu na GTX 260 DirectCompute pade za 50% dol v primerjavi z OpenCL (!!) je zaključek, da je CUDA (!!) še vedno boljša? Kaj je potem šele zaključek za Radeon-e, kjer so enostavno failal vsi OpenCL testi, na obeh karticah? Eko praktično isto vprašanje zate, kot sem ga postavil Firesnake-u: Kaj je razlika med DirectCompute in OpenCL (ali pa CUDA).
Ampak najprej mora AMD ujet NV glede samega OpenCL/DirectCompute...
Hja, se bodo ze mogli zmigat. Zaenkrat se nic ne kaze, da bi v tej smeri sli s kakimi vecjimi koraki. Tudi zasledil nisem nic, glede tega, zadnje case.
Azgard: Ja super par random cifer. Vsaj razlike med CUDA, OpenCL in DirectCompute bi si pogledal na drugem linku, ki si ga dal. Na Geeks3D pa bi vsaj tam na desni OpenCL test kliknil in pogledal. In ker na drugem linku v enem testu na GTX 260 DirectCompute pade za 50% dol v primerjavi z OpenCL (!!) je zaključek, da je CUDA (!!) še vedno boljša? Kaj je potem šele zaključek za Radeon-e, kjer so enostavno failal vsi OpenCL testi, na obeh karticah? Eko praktično isto vprašanje zate, kot sem ga postavil Firesnake-u: Kaj je razlika med DirectCompute in OpenCL (ali pa CUDA).
Očitno ti nisi mojega posta prebral, jaz sem rekel IZKLJUČNO v DirectCompute(verzija 5, ki je v DX11) da je 5850 4krat bolši od fermi, kar je res. O Cuda sploh nisem govoril, jasno da je boljša, to je nekako splošno znano, drugi link pa vseeno pokaže da razlika ni lih tolko gromozanska, no zadosti velika da je CUDA jasno izbira kjer je P/P važen. Kar se zmogljivosti tiče. CUDA ma pa itak prednost še zaradi tega, ker podpira C kodo direktno.
Ponavadi tudi grafične v PC-ju nahitreje zastarijo.(Ponavadi zamenjam dve grafični na leto, zdaj se lahko zahvalim Nvidiji, da bom celo leto imel samo eno.) Nvidia je razmišljala dolgoročno in bolj široko samo je potegnila takratko. Ko bo vse to enkrat razvito in v uporabi, bo AMD že imel pripravljen odgovor.
Azgard: In kako veš, da tisti Geeks3D test uporablja točno DirectCompute 5 in ne 4 ali 4.1? Mislim kompleten DirectCompute (4.0, 4.1) je na voljo samo v DX11. In ker en test pravi tako, potem to drži univerzalno za vse kar se da na tem svetu sprogramirat. Pa si že videl kakšen kos C for CUDA ali pa OpenCL kode (ali pa DirectCompute), da trdiš, da podpira "C kodo direktno"?
Sentinel: jaz sem videl vsaj 5 testov, ki kažejo to razliko v DirectCompute med ATI in Nvidia, dal sem pa prvi link, ki sem ga nahitro našel. Če trdiš nasprotno najdi link, ki trdi nasprotno, potem pa si bom vzel cajt, da najdem prave reviewe, jaz sem namreč že prepričan, ker sem kake pol leta mel preveč cajta pa sem se pozanimal o DirectCompute, Nimam pa nobene prakse z temi APIji, o podpori C-ja v Cudi sem bral, da je to veliko prednost, to je vse, če ni so pač tam lagali/zavajali. In če niti te prednosti ni pri Cudi, potem bo zanimivo gledat, kaj bo dolgoročno Cuda sploh uspela.
Torej Cuda res ne zna compilat standardne C kode, ampak ima svojo? Ti povej, ne pa da mene sprašuješ, jaz sem o tem samo bral.
Ja, tudi dolar raste iz 1,40 na 1,21...to ima več veze kot pomanjkanje konkurence.
Se strinjam, to je verjetno glavno za dvig cen... GRKI !
"Rad pomagam, če je le možno" by Fr4nc; blog(2): http://cpuwars.wordpress.com/
"I just love to share the truth!!" by Fr4nc; http://intelvsamd.wordpress.com/
PIPI: Ne, ampak razlog, ki ga fani tko pogosto vlečejo na dan je, da je za igranje sodobnih iger sposobnih PC-jev tako malo, da so konzole edini market.
Sentinel: jaz sem videl vsaj 5 testov, ki kažejo to razliko v DirectCompute med ATI in Nvidia, dal sem pa prvi link, ki sem ga nahitro našel. Če trdiš nasprotno najdi link, ki trdi nasprotno, potem pa si bom vzel cajt, da najdem prave reviewe, jaz sem namreč že prepričan, ker sem kake pol leta mel preveč cajta pa sem se pozanimal o DirectCompute,
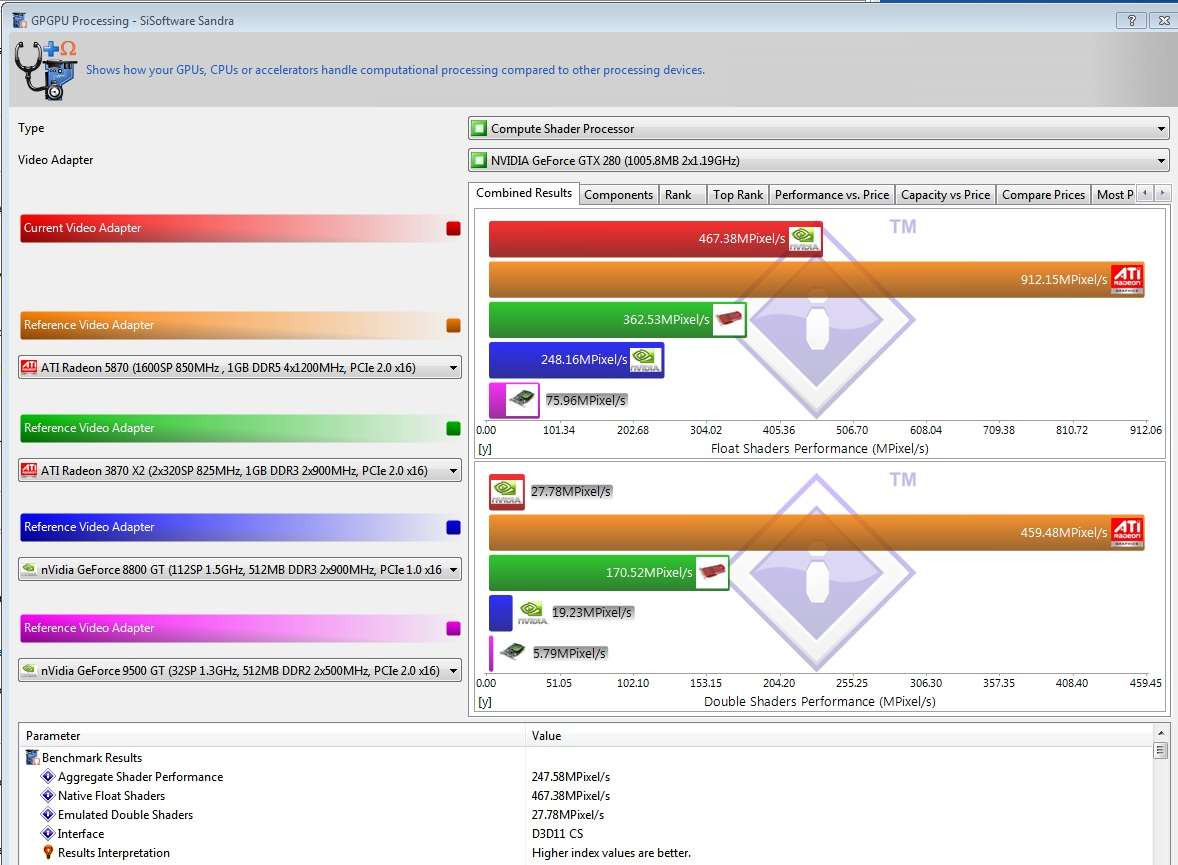
5 testov si videl? Jaz nisem našel enega približno uporabnega. Ajde recimo Sisoft Sandra 2010 klik - GTX 280 vs. 5870. Za vzet s precejšnjo mero soli, ampak hej GTX 280 je samo 2x počasnejši od 5870, kar je očito čudež, ker je GTX 470 4x počasnejši od 5850.
Nimam pa nobene prakse z temi APIji, o podpori C-ja v Cudi sem bral, da je to veliko prednost, to je vse, če ni so pač tam lagali/zavajali. In če niti te prednosti ni pri Cudi, potem bo zanimivo gledat, kaj bo dolgoročno Cuda sploh uspela.
Torej Cuda res ne zna compilat standardne C kode, ampak ima svojo? Ti povej, ne pa da mene sprašuješ, jaz sem o tem samo bral.
Noben pri zdravi pameti NOČE kar neke xy standardne C kode prevajat za GPGPU. Ampak, če stvari niti od daleč ne pogledaš in bereš PR crap od ljudi, ki stvari tudi niso od blizu pogledal... Eko kernel v C for CUDA:
__global__ void VecAdd(const float* A, const float* B, float* C)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
C[i] = A[i] + B[i];
}
Eko isti kernel v OpenCL:
__kernel void VecAdd(__global const float* A, __global const float* B, __global float* C)
{
int i = get_global_id(0);
C[i] = A[i] + B[i];
}
In še DirectCompute:
StructuredBuffer<float> A : register( t0 );
StructuredBuffer<float> B : register( t1 );
RWStructuredBuffer<float> C : register( u0 );
[numthreads(512, 1, 1)]
void VecAdd(uint3 i : SV_DispatchThreadID)
{
C[i] = A[i] + B[i];
}
Vidiš kakšno posebno razliko? Zakaj bi potem bila kakšna posebna razlika v performancah? Če je razlika med dvema variantama na istem hardware-u, potem je ali driver f*** up ali pa vse tri variante pač ne počnejo vsega enako in so primerljive toliko kot hruške in jabolka.
Vidiš kakšno posebno razliko? Zakaj bi potem bila kakšna posebna razlika v performancah? Če je razlika med dvema variantama na istem hardware-u, potem je ali driver f*** up ali pa vse tri variante pač ne počnejo vsega enako in so primerljive toliko kot hruške in jabolka.
ponavad je kr drajver kriv, še acelerator iz c# nardi dost dobro kodo na dx9. tle ma ati še kr neki za postorit. ker kerneli so provzaprov neki precej preprostga.
Zelo kratkorocno? Igracar bo kupil kartico za poganjanje iger. In to se niti dolgorocno ne bo spremenilo. Ce bi stevilke, ki so objavljene v prid rdecemu taboru veljale za zeleni tabor, bi se pa lahko sekirali, ker bi to lahko poemilo to, da zeleni pritisnejo s svojim standardom. Tako pa, IMHO ni bojazni, saj njihova beseda na trgu skorajda irelevantna. In kako se zraven spravljajo bo se lep cas tako ;)
ponavad je kr drajver kriv, še acelerator iz c# nardi dost dobro kodo na dx9. tle ma ati še kr neki za postorit. ker kerneli so provzaprov neki precej preprostga.
Tole je pa tudi ena vecjih neumnosti, kar sem jih zadnje case prebral, sploh zadnji del.
Hja, ne spoznam se ravno na te novotarije, samo kolikor sem bral je tudi dosti odvisno od arhitekture.
Vprašanje je če je ista koda napisana za nvidia kartico sploh primerljiva na ati kartici. Mislim da enostavno ne. Če se reči prilagodi bo pač delalo boljše, saj je vedno tako.
Seveda nvidia vlaga dosti več ravno tu, da "prepriča" čimveč programerjev, da optimizirajo na nvidio. Seveda, pri igrah si to ne morejo ravno privoščit software firme, da igra ne bi delovala na določeni moderni strojni opremi. Se pa pozna pogosto da kaj ne deluje.
Podobno je tudi compute, če je pritisk kupcev dovolj močan bodo pač morali vključit še kakšne alternative. Glede na 5xxx boom ne dvomim da se bo kje pojavil še ati-path za izkoriščanje grafičnih zmogljivosti. Slej ko prej, seveda pa to traja.
No če se ne bo, bo to dolgoročno dokaj slabo. Saj bomo morali kupivati po dve grafični, eno nvidio pa en ati in ne bo neke prave izbire.
1) Seveda nvidia vlaga dosti več ravno tu, da "prepriča" čimveč programerjev, da optimizirajo na nvidio. Seveda, pri igrah si to ne morejo ravno privoščit software firme, da igra ne bi delovala na določeni moderni strojni opremi. Se pa pozna pogosto da kaj ne deluje.
2) Glede na 5xxx boom ne dvomim da se bo kje pojavil še ati-path za izkoriščanje grafičnih zmogljivosti. Slej ko prej, seveda pa to traja.
1) Zeleni kar posodijo programerje hisam, ki razvijajo spile. Zelo agresivna taktika.
2) Ja, se strinjam, malo bi se lahko zmigali v tej smeri.


{kind=link}