Forum » Strojna oprema » AMD ZEN - nova X86 Jedra
AMD ZEN - nova X86 Jedra

Predator X ::
Potem preko 40gb/s. Zdej je pa tolk hitr kot l3 sam ma nizji clock
x45 ::
Xeon x3430, 8 GB DDR3, Matrox grafa
iloveboobz ::
Potencialno lahko pridobiš nekaj L3 cacha z 2+2, to je pa tudi edina prednost.
če bi se amd odloču, da da tudi 4 core partom 16MB. Ampak je vseeno bolje, da so vsa jedra na istem CCXu.
Predator X ::
iloveboobz je izjavil:
Potencialno lahko pridobiš nekaj L3 cacha z 2+2, to je pa tudi edina prednost.
če bi se amd odloču, da da tudi 4 core partom 16MB. Ampak je vseeno bolje, da so vsa jedra na istem CCXu.
Noben tega dela ne razloži dobr.
Sej kokr vidš v špilih ni velik problemov so le izjeme.
iloveboobz ::
Predator X ::
iloveboobz je izjavil:
z apuji sigurno nebo težav, ker bodo mel samo en CCX. Sam vprašanje če bodo mel kej L3ja
Ta CCX ma več kot 100GB/s.
D3m0r4l1z3d ::
A1nCWrFBMK2NmkycgVN4sAwhvY8YyNNbF6KUSJyFZ99QKU8phCn
Cryptopia ref. link: https://www.cryptopia.co.nz/Register?referrer=Anymalus
Predator X ::
iloveboobz je izjavil:
o kakih 100GB/s ti sanjaš ?
Data fabric ima 32b/cycle. (stock 1033MHz)
L3 cache ima 32b/cycle. (stock = core clock = 3GHz+)

iloveboobz ::
https://www.techpowerup.com/forums/thre...
However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
Predator X ::
iloveboobz je izjavil:
32B/cycle je za L3, ne za CCX
https://www.techpowerup.com/forums/thre...
However, even if we were to distribute workload in-between two different cores from each CCX, so as to be able to access the entirety of the 1800X's 16 MB cache... we'd still be somewhat constrained by the inter-CCX bandwidth achieved by AMD's Data Fabric interconnect... 22 GB/s, which is much lower than the L3 cache's 175 GB/s - and even lower than RAM bandwidth. That the Data Fabric interconnect also has to carry data from AMD's IO Hub PCIe lanes also potentially interferes with the (already meagre) available bandwidth
The Stilt
The data fabric
The northbridge of Zeppelin is officially called as the data fabric (DF). The DF frequency is always linked to the operating frequency of the memory controller with a ratio of 1:2 (e.g. DDR4-2667 MEMCLK = 1333MHz DFICLK). This means that the memory speed will directly affect the data fabric performance as well. In some cases, it may appear that the performance of Zeppelin scales extremely well with the increased memory speed, however that is necessarily not the case.
In many of these cases the abnormally good scaling is caused by the higher data fabric clock (DFICLK) resulting from the higher memory speed, rather than the increased performance of the memory itself.
The highest officially supported memory speed for consumer (AM4) Zeppelin parts is 2667MHz (two single rank / sided modules in total) or 2400MHz (two dual rank / sided modules in total), however memory ratios for 2933MHz and 3200MHz speeds are available (not officially supported), at least on some motherboards.
iloveboobz ::
Predator X ::
{kind=link}
iloveboobz je izjavil:
1:2 ratio pr 2667MT ramu pomeni efektivno 667Mhz, ne 1333Mhz, saj je ddr4 double data rate.
Nerazumeš.
Zgodovina sprememb…
- predlagal izbris: SuperVeloce ()
iloveboobz ::
Nerazumeš.
ti ne razumeš fundamentalnih zadev pri dramu
2667MT ram interno laufa na 1333Mhz, ne 2667
Zgodovina sprememb…
- spremenil: iloveboobz ()
Predator X ::
iloveboobz je izjavil:
Nerazumeš.
ti ne razumeš fundamentalnih zadev pri dramu
Okay
iloveboobz je izjavil:
Nerazumeš.
ti ne razumeš fundamentalnih zadev pri dramu
2667MT ram interno laufa na 1333Mhz, ne 2667
A si se le popravil. Sej sm že prej pisal data fabric clock = 1:2 DDR
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Predator X ::
iloveboobz je izjavil:
Če ti matematika ne gre, bandwidth med ccxi je polovico od DRAM bandwidth-a. Torej 100GB/s je pač nemogoče, kot ti trdiš
50GB/s v eno in 50GB/s v drugo.
Predator X ::
iloveboobz je izjavil:
In od kje si zdej potegnu 50GB/s ?
DDR4 3200MHz
Sej poglej benche AIDA, če ima 2667/2993/3200MHz DDR4 se latenca pri L3 tako giblje pri 20ns.
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Naredi izračun za 2667 (uradno maks podprto) in dobiš ven 21.3GB/s, kar je zelo blizu 22GB/s, o katerem je skos govora.
Sej poglej benche AIDA, če ima 2667/2993/3200MHz DDR4 se latenca pri L3 tako giblje pri 20ns.
latenca l3ja nima nobene veze z hitrostjo ddr4, ker hitrost l3ja je vezana na core, ne na memclk
Zgodovina sprememb…
- spremenil: iloveboobz ()
Predator X ::
iloveboobz je izjavil:
In zdaj to razpolovi in dobiš ven 25GB/s v eno smer.
Naredi izračun za 2667 (uradno maks podprto) in dobiš ven 21.3GB/s, kar je zelo blizu 22GB/s, o katerem je skos govora.
Kaj zdej že spet bluziš? Prav nič ne preberš... bluziš po svoje.
Zgodovina sprememb…
- predlagal izbris: SuperVeloce ()
iloveboobz ::
Fact of the matter is, med CCXi se _nikol_ ne prenaša z 100GB/s.
Zgodovina sprememb…
- spremenil: iloveboobz ()
Predator X ::
iloveboobz je izjavil:
Ti bluziš po svoje, ker si zmišljuješ svojo definicijo bandwidth-a.
Fact of the matter is, med CCXi se _nikol_ ne prenaša z 100GB/s.
Še zadnjič
The Data Fabric is reponsible for the core’s communication with the memory controller, and more importantly, inter-CCX communication. As previously explained, AMD’s Ryzen is built in modular blocks called CCX’s, each containing four cores and its own bank of L3 cache. An 8 core chip like Ryzen contains two of these. In order for CCX to CCX communication to take place, such as when a core from CCX 0 attempts to access data in the L3 cache of CCX 1, it has to do so through the Data Fabric. Assuming a standard 2667MT/s DDR4 kit, the Data Fabric has a bandwidth of 41.6GB/s in a single direction, or 83.2GB/s when transfering in both directions. This bandwidth has to be shared between both inter-CCX communication, and DRAM access, quickly creating data contention whenever a lot of data is being transfered from CCX to CCX at the same time as reading or writing to and from memory.
2667MHz DDR4
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Assuming a standard 2667MT/s DDR4 kit, the Data Fabric has a bandwidth of 41.6GB/s in a single direction, or 83.2GB/s when transfering in both directions.
to je zajeb, zato ker data fabric je na polovični frekvenci drama, torej nikakor nemore bit bandwidth enak dramu. Dej nared izračun, pred vse slepo verjameš.
Predator X ::
Poglej 5 stran 1600MHz memory bus.
20ns L3 in ne 42ns+-
iloveboobz je izjavil:
Assuming a standard 2667MT/s DDR4 kit, the Data Fabric has a bandwidth of 41.6GB/s in a single direction, or 83.2GB/s when transfering in both directions.
to je zajeb, zato ker data fabric je na polovični frekvenci drama, torej nikakor nemore bit bandwidth enak dramu. Dej nared izračun, pred vse slepo verjameš.
Sej data fabric ma 64b/cycle v obe smeri oziroma 32b/cycle v eno stran.
Zgodovina sprememb…
- spremenilo: Predator X ()
Predator X ::
iloveboobz je izjavil:
še enkrat, od kje ti ideja da je data fabric 32b/cycle ?
AMD slide. Že 10x sem ti poslal.
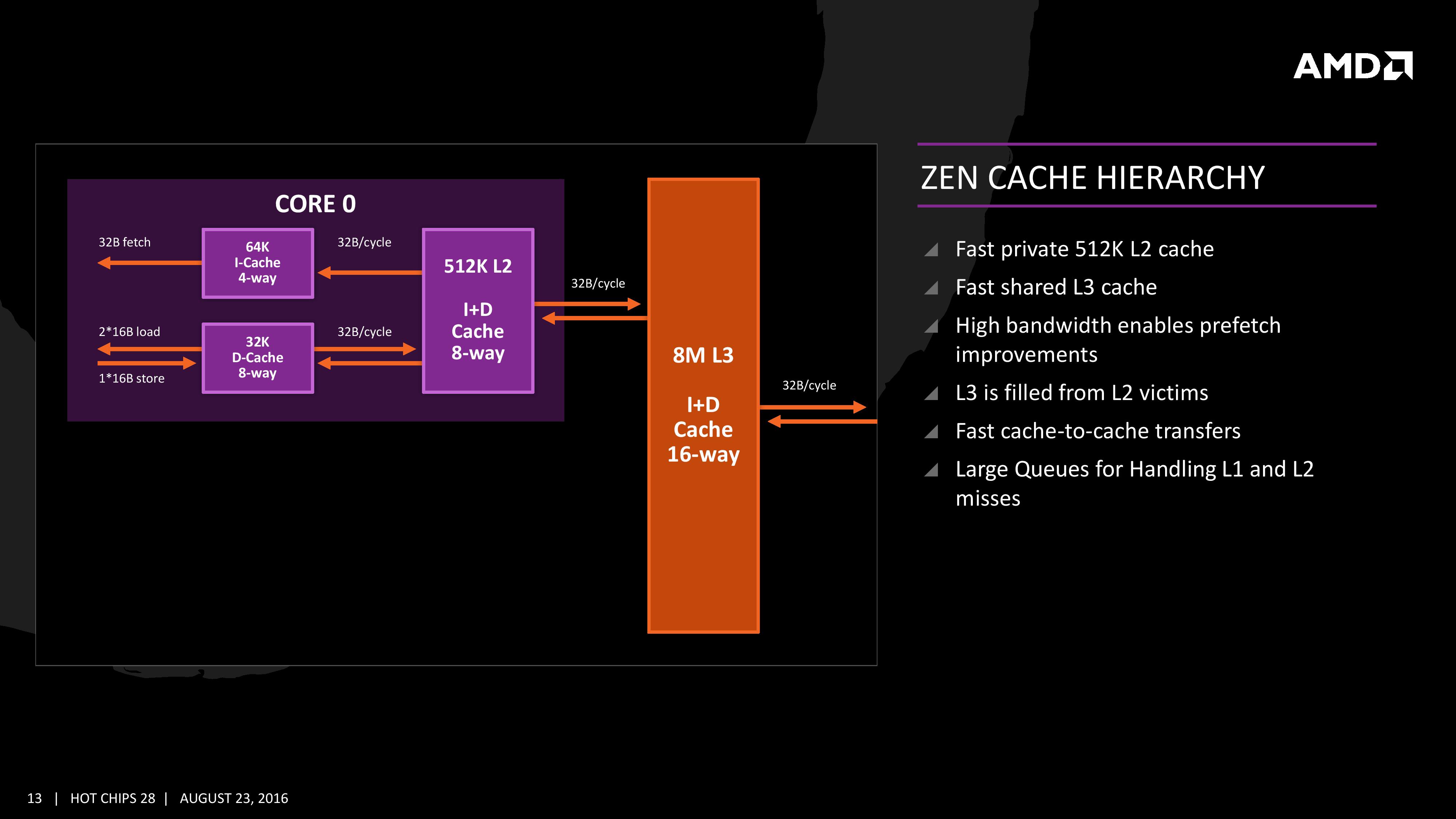
tole je zadnjič
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Zgodovina sprememb…
- spremenil: iloveboobz ()
Predator X ::
iloveboobz je izjavil:
Ok, potem pa razloži, zakaj ma L1/l2 tolk višji bandwidth in nižjo latenco, če ma še vedno 32b/cycle
Aa? zdej si počas začel dojemat da se motiš?
https://thetechaltar.com/amd-ryzen-cloc...
https://i1.wp.com/thetechaltar.com/wp-c...
{kind=link}
Zgodovina sprememb…
- spremenilo: Predator X ()
Predator X ::
iloveboobz je izjavil:
še eni, ko jim dela matematka probleme.
Zgleda, da se vsi motimo edino ti imaš prav.
Zgodovina sprememb…
- predlagal izbris: SuperVeloce ()
Predator X ::
iloveboobz je izjavil:
Kateri del polovičnega bandwidtha ti in tvoje čungalunga strani ne razumejo ?
Da si tolk počasn... tudi prav.
Lp
iloveboobz ::
Predator X ::
iloveboobz je izjavil:
Pa sej grafi pinganja jeder od pcper povedo vse. Sploh ni treba fantazirat o 100GB/s ali 22GB/s, dejstvo je, da je data fabric počasen in v določenih primerih hud bottleneck.
Kateri ram so uporabili?
D3m ::
Za enkrat ni še nič z njihove strani.
Zgodovina sprememb…
- spremenil: D3m ()
iloveboobz ::
Interesting stuff. I think your conclusion is bang-on (that overall L3 cache performance will be affected greatly by memory clock), but your math in the first 3 paragraphs might be a little off.
The way I see it, the total bandwidth of the infinity fabric is related to the memclk, but the total bandwidth of the RAM itself and the dual-channel dual-CCX configuration is only semi-relevant. The fabric moves 32 bytes per cycle from each L3 - for a memclk of 1333 (to take your example), that means a peak performance of 42.6GB/s bandwidth per CCX.
So the question then, is why does the article say the inter-CCX bandwidth is only 22GB/s? The answer to that is that the bandwidth from L3 must be shared between the interconnect and the main memory. Consider a case where you've queued data to move to RAM and the same data to be moved to the other CCX - great! We get 32 bytes from L3 and move it to both locations simultaneously. No harm, no foul. Now consider a case where you've queued data to move to RAM and different data in the next cycle needs to move to the other CCX. You've basically just cut the fabric's efficiency in half compared to the previous scenario.
Predator X ::
Od pcper prosijo za njihovo izvorno kodo za testiranje, da še drugi preizkusijo.
Za enkrat ni še nič z njihove strani.
Nič novega. Tud tole z gamingom mi ni ravno jasno kaj točn hočjo povedat.
Sej v osnovi si core ne deli L cacha.
iloveboobz je izjavil:
ta ti bo malo lažje
Interesting stuff. I think your conclusion is bang-on (that overall L3 cache performance will be affected greatly by memory clock), but your math in the first 3 paragraphs might be a little off.
The way I see it, the total bandwidth of the infinity fabric is related to the memclk, but the total bandwidth of the RAM itself and the dual-channel dual-CCX configuration is only semi-relevant. The fabric moves 32 bytes per cycle from each L3 - for a memclk of 1333 (to take your example), that means a peak performance of 42.6GB/s bandwidth per CCX.
So the question then, is why does the article say the inter-CCX bandwidth is only 22GB/s? The answer to that is that the bandwidth from L3 must be shared between the interconnect and the main memory. Consider a case where you've queued data to move to RAM and the same data to be moved to the other CCX - great! We get 32 bytes from L3 and move it to both locations simultaneously. No harm, no foul. Now consider a case where you've queued data to move to RAM and different data in the next cycle needs to move to the other CCX. You've basically just cut the fabric's efficiency in half compared to the previous scenario.
Dobr poglejte sliko.
https://i1.wp.com/thetechaltar.com/wp-c...
Res dobr poglej.
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Ampak še vseeno, worst case scenario je pa lahko res polovica bandwidth-a.
Zgodovina sprememb…
- spremenil: iloveboobz ()
Predator X ::
iloveboobz je izjavil:
Sj maš prav, da boš lažje spal. V perfektnem svetu lahko res premikaš z 41GB/s (razlaga stilta je res malo butasta, ker če na hitro pogledaš, zveni kot da je res prepolovljen bandwidth).
Ampak še vseeno, worst case scenario je pa lahko res polovica bandwidth-a.
Ni res, sej ti slika pokaže vse.
Noben ne bo lažje spal zaradi teh pogovorov, ker ima vsek čist druge probleme.
Zgodovina sprememb…
- predlagal izbris: SuperVeloce ()
Predator X ::
iloveboobz je izjavil:
Ni res, sej ti slika pokaže vse.
32b*1333Mhz=42656MB/s
V eno smer.
Ti res misliš, da bi bla stvar tolk hitra z 22,6GB/s? To pa je čudno, potem bi vsi čakal na 1xCCX čip. Vse skup so mal zabluzili.
Zgodovina sprememb…
- spremenilo: Predator X ()
iloveboobz ::
Predator X ::
iloveboobz je izjavil:
Nwm, kako hitra bi bla zadeva z 22GB/s, je pa jasno, da je to lahko worst case scenarij, kot razloži zgoraj post.
Pcper je zabluzil.
Data fabric ima počasnejšo komniciranje kot pa dva čipa z hitrjšim DDR3jem. Sure.