Ars Technica - V četrtek je ARM na novinarski konferenci v kalifornijski Santa Clari predstavil tehnične podrobnosti nove generacije arhitekture ARMv8, ki končno prinaša podporo za 64-bitno izvrševanje ukazov. Prvi procesorji z ARMv8 bodo na voljo prihodnje leto, prvi prototipi sistemov, ki jih bodo uporabljali, pa leta 2014.
ARM je najbolj priljubljena med RISC-arhitekturami (medtem ko je x86, ki jo imamo v osebnih računalnikih, CISC), ki jo v veliki meri uporabljamo, kadar sta ključni nizka cena in nizka poraba energije. Zato ni presenetljivo, da je velika večina procesorjev v pametnih telefonih, predvajalnikih glasbe, tabličnih računalnikih in vrsti drugih naprav prav arhitekture ARM. Vsi ti procesorji so 32-bitni (v resnici imajo že 40-bitno virtualno naslavljanje za dostop prek 4 GB pomnilnika), sedaj pa je ARM v želji po uporabi svojih procesorjev tudi v zahtevnejših okoljih predstavil 64-bitno arhitekturo. Že lani pa so napovedali tudi podporo večnitenju.
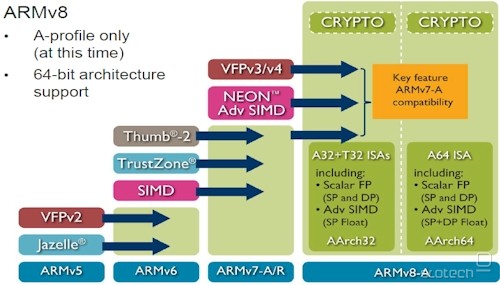
Novi ARMv8 bodo nazaj združljivi s prejšnjimi generacijami. To bodo dosegli tako, da bodo lahko izvajali ukaze v dveh načinih - stari AArch32 bo združljiv z ARMv7, medtem ko novi AArch64 jasno ne bo. S tem želi ARM poseči tudi na del trga, ki je bil doslej rezerviran za Intel in AMD, to je na področje domačih osebnih računalnikov, strežnikov in podatkovnih centrov. Mnogi proizvajalci so povedali, da dokler ARM ne bo 64-biten, ga v svoje sisteme ne bodo vključili. Sedaj bo prilaganje kode programov, ki so pisani za x86-64, Itanium, MIPS in druge 64-bitne arhitekture, lažje. ARMv8 ima vgrajeno strojno podporo za šifriranje AES, zgoščevalna algoritma SHA-1, SHA-256, virtualizacijo, TrustZone (podprta že od ARMv6) in ukaze NEON SIMD (že od ARMv7).
S prehodom v 64-bitni razred je ARM postal resnejši konkurent, a časa nimajo na pretek. Druga polovica prihodnjega leta, ko naj bi ugledali šele prve procesorje, saj bo ARM šele tedaj licenčnim partnerjem razkril podrobne specifikacije za profile ARMv8 A, je namreč še zelo oddaljena. Še dosti bolj oddaljeno je leto 2014, ko naj bi dočakali prve sisteme za končne uporabnike. Intel in AMD bosta do takrat zagotovo kaj storila s svojimi procesorji. Medtem naj bi bil Hewlett-Packard prvi kandidat, ki bo svojih strežnikih uporabil čipe ARM.
and b4: ARM spuši v procesorski moci proti SB, buldo/ kako bos delal rendering videov itd... CUDA, cloud (http://www.renderbay.com/)... glavno je, da je proc dost mocan za tistih 90% opravil, za preostalih 10% se pa ze da kaj narediti (ze omenjena cuda, cloud alpa pac par x86 postaj na sihtu). edino ne vem, kako bo ARM lavfal sodobne igrice... NEON je pomoje bolj tko-tko, kar se tice FPU zmogljivosti.
Ja, Niti Intel niti AMD se nista naučila poante iz zgodbe o netbookih: good enough tech! Samo to.
Čisti consumer bodo verjetno z lahko prešaltal na Win8 na ARMu, storage bo na cloudu, GUI pa enak. Tale WIntel eko sistem je pod vprašanjem. In luknje vanj ni zvrtal linux ampak kratkovidnost na HW strani.
Saj v tem je fora. AMD je imel prekleto veliko časa da si omisli svojo novo arhitekturo. Mislim, če ravno ne mara ARMa MIPSA itd.
Komot naredijo kaj svojega, po možnosti odprejo specse tudi za druge, mogoče proti plačilu licenčnine ali kaj takega in piči miško.
Sploh ker stalno sanjajo o Fusionu. Z novim coreom komot naredijo blend. Par "fat coreov" predvsem za CPU computing, več deset lean coreov za pomožne zadeve in večsto ultralean coreov kot shaderji recimo.
Ki je večino časa ne potrebuješ in jo zlahka vključiš po potrebi.
kako? saj sam proc je zelo limited po compute capability, razen ce jih vkljucis par (deset) se zraven.
brane2 kaj pa fusion? je to res, da se jim gre tut za to, da bi kompletno integrirali graficno v cpu (torej da bi na zunaj zgledala kot ena sama enota) in bi lahko grafika preracunavala fpu zadeve (prek kaksne decode x86 - > VLIW enote sklepam, ce je to mozno)
Vse kar so popkazali, je kao nizek latency. Valjda, če stvar laufa iz istega RAM-a.
Poleg tega, koga je briga latency. Stvari se itak preračunavajo v batchih.
Poleg tega, niso pokazali to, kar je folk pričakoval od njih- inteligentne shaderje. Če rineš GPU tja, kjer je bil prej FPU, mu moraš dati neko inteligenco, neko avtonomnost. Če tega ni, kurc, pol nisi veliko naredu.
Zaradi tega mi je všeč Intlova ideja o polju CPUjev. Mislim, x86 je nagravžen, ampak ideja o vsaj neki avtonomnosti ni slaba. Preveč je jasno ne more biti, ker potem ne prišparaš nič.
to je res ja. gpuji bodo itak vazni za igranje igric, ko bo to vse skup na desktopu, takrat se jih bo pa pac izkoristilo se za to. sam to je tut bistvo amd fusion afaik. brane nizek latency? a nimata zdaj kao cpu in gpu istega memory controllerja? mogoce je malo beefed up, ampak meni se to zdi fajn drawback.
Kar se cloudov tiče, cloud me lahko vidi samo ob kakem udaru letala v goro zakrito v oblaku ali mogoče kot posledica bombe v letalu ali kaj podobnega...
Po tem kar sem jaz razumel je 64-bitna ARM arhitektura predvsem zanimiva za server okolje, kjer se gre "uporabniku" za čim manjšo porabo pri veliki količini procesorjev. Zanima jih pa velika količina procesorjev ker rabijo MIMD arhitekturo. To pomeni da se na več različnih podatkih uporablja več različnih ukazov. Sama hitrost obdelave ni tako pomembna, ker je nivo paralelizacije visok, ker je veliko zahtevkov ki so med sabo "neodvisni".
Pri "marcinah" kot so intel in AMD procesorjih, je cilj imet čim hitrejšo izvedbo več zaporednih ukazov, ker je želja po hitri izvedbi programov z nizkim nivojem paralelizacije (zahtevki so odvisni eden od drugega). SIMD, MIMD in MISD arhitekture niso tako pomembne.
GPU je pa zopet čisto drugačna zverina. Je zverina ki dela po principu visoke paralelizacije, kjer se pa lahko masa podatkov obdeluje z istim zaporedjem ukazov, jasno branchi niso zaželeni (SIMD arhitektura).
Vsak od teh pristopov ima svoje prednosti in slabosti. Vsak je primeren za svoj tip aplikacije.
Ali sem jst samo cisto zablodo za kaj se gre tukaj?
to je v sodelovanju z nvidio, ali ta z svojim project denver odkriva toplo vodo?
ziga, ko bo podpora za win na arm, bo vse, kar bos rabil (ob predpostavki, da bodo knjiznice ala stl dobro postimane) drug flag pri compilanju. zaenkrat pa tega res se ni in je najboljsa pot do performansov inline asm (vsaj za fpu/ neon).
to je v sodelovanju z nvidio, ali ta z svojim project denver odkriva toplo vodo?
ziga, ko bo podpora za win na arm, bo vse, kar bos rabil (ob predpostavki, da bodo knjiznice ala stl dobro postimane) drug flag pri compilanju. zaenkrat pa tega res se ni in je najboljsa pot do performansov inline asm (vsaj za fpu/ neon).
Hm, ne vem kaj je na ARM-u tko posebnega ampak men se zdi npr dosežek AMD Fusion platforme neverjeten in res ne vidim fore v ARM-u. Vsaj ne kar se tiče laptopov in netbookov. Telefoni in tablice pa so segment kjer ARM blesti. In mislim, da bo tam tud ostal, Microsoft pa forsira podporo ARM-a ravno zaradi tablic kjer nima neke hude pokritosti in kjer jim Apple z iPad-om odžira lep delež trga.
a je ta fusion zaenkrat (!) slucajno enaka zadeva kot sandy bridge graphics? zaenkrat naj bi bil to afaik samo gpu na isti rezini kot cpu, s tem, da si se delita mem controller, kar tut ni lih fajno...
Hm, kakor sem gledal sheme samega čipa je CPU in GPU del dejansko združen v en sam čip in ne kot so imel prvi netbook procesorji, kjer so pač zbasali CPU in GPU na isto pakiranje. Zato jih tud imenujejo APU in ne CPU+GPU. Sem spada celotni range C in E čipov, pa še neki G naj bi bili ampak to so za tablice in telefone če sem prav zastopil.
Kakorkoli že, upam, da bo ARM dobra konkurenca, ker konkurenca je vedno dobrodošla, kakršnakoli že je.
>Hm, ne vem kaj je na ARM-u tko posebnega ampak men se zdi npr dosežek AMD Fusion platforme neverjeten in res ne vidim fore v ARM-u armi nudijo zelo dober performance/W in performance/€, torej so super za netbooke/laptope pri katerih je glavno trajanje baterije, teža, cena
imajo pa seveda to slabost, da ne podpirajo x86 programov, kar pomeni, da rabiš nove verzije vse programske opreme
za opensource to ni tako velik problem, za closedsource si pa v riti, ker tudi če izide arm verzija jo boš moral kupit posebej in je ne boš dobil zastojn, čeprav si že lastnik x86 verzije
seznam zanč moderatorjev in razlogov da so zanč
http://pastebin.com/QiWny5dV
gor je mavrik apple uporabniček (mali možgani in mali penis)
hm, ce prav razumem, je dandanes cpu posebej, na gpu pa lahko offloada prek opencl oz. hw dekodiranja malo dela (ala tisti intel quick sync al kaj je ze), bo pa v prihodnosti to bolj integrirano. ceprav ne vem, ce je decode za x86 - > radeon vliw sploh mozen... brane, jst?
>imajo pa seveda to slabost, da ne podpirajo x86 programov, kar pomeni, da rabiš nove verzije vse programske opreme
to ni tak problem, je dokazal apple z svojim ios. kvecjemu bolje, da se znebimo vse zalege, ker bi potem tako cpu kot os morala podpirati vse dirty hacke za nazaj in bi bili prakticno tam, kjer smo sedaj...
Kakor sem bral nekje drugje naj bi ARM imel nek x86 način, tako da naj bi vse obstoječe aplikacije isto delovale. Nimam pojma če sem prav razumel, ampak vem da sem nekaj zasledil okoli tega.
>Kakor sem bral nekje drugje naj bi ARM imel nek x86 način, tako da naj bi vse obstoječe aplikacije isto delovale. Nimam pojma če sem prav razumel, ampak vem da sem nekaj zasledil okoli tega. tuki se gre pomoje za kako emulacijo, torej performance = drek
@trnvpeti armi v telefonih majo porabo okrog kakega watta, v računalniku bojo sigurno imeli višjo, ampak še vedno dost manjšo od sb/ivb pa moraš upoštevat, da zaenkrat arm nima namena konkurirat x86 procesorjem v hitrosti - če rabiš kar se da hitro izvajanje programov, armi niso zate ampak večina uporabnikov tega ne rabi, rabi pa manjše gretje, cenejše čipe, ..
seznam zanč moderatorjev in razlogov da so zanč
http://pastebin.com/QiWny5dV
gor je mavrik apple uporabniček (mali možgani in mali penis)
hm, ce prav razumem, je dandanes cpu posebej, na gpu pa lahko offloada prek opencl oz. hw dekodiranja malo dela (ala tisti intel quick sync al kaj je ze), bo pa v prihodnosti to bolj integrirano. ceprav ne vem, ce je decode za x86 - > radeon vliw sploh mozen... brane, jst?
Dandanes je CPU (logično) posebej in GPU (logično) posebej, čeprav sta fizično na isti rezini. Latency je v tem primeru s stališča GPU-ja še vedno precej boljši, kot na običajnih grafičnih karticah. Sicer pa se naredi translacija recimo iz SSE/AVX v to kar GPU-jevi ALU-ji zastopijo. To ni tak problem, večji problem bo spravljat podatke iz enega konca čipa na drugega. Recimo že compute je na današnjih GPU-jih povsem ločen način obratovanja GPU-ja. Lahko imaš grafiko (pixel/vertex/geometry/domain/hull shaderje) ali pa compute shaderje. Oboje sočasno ne gre.
Kakor sem bral nekje drugje naj bi ARM imel nek x86 način, tako da naj bi vse obstoječe aplikacije isto delovale. Nimam pojma če sem prav razumel, ampak vem da sem nekaj zasledil okoli tega.
bullshit. za emulacijo na hw nivoju bi rabili licenco in VELIKO vec energije (glej itanium, ki ima to), na sw nivoju pa veliko energije in bolj kompleksen design proca za zanic delovanje. da o raznih legacy programih, ki izkoriscajo kaksne bedne old-times nacine za delovanje, katere morajo winsi (in proci) se vedno podpirat, niti ne govorim.
pa itak gre apple ipadu cist dobro, gor pa ne dela NOBEN program za navadne apple.
senitel da ni bil tisto intel? tale qualcomm pa zdaj zene bajne denarce na racun optimiziranih arm procev. samo a licence pa ne morejo ponovno kupit? ampak to so eni in isti shaderji, ki se jih preprogramira, right?
Saj so imeli svoj ARM team. Čisto uspešna zadeva. Potem so pa vse skup prodali Qualcomu.
ČISTI kretenizem IMHO. Za tole bi morali tistega CEO-ta ustrelit. Dobesedno. Domneval sem, da so to naredili namerno, ker že imajo ali pa imajo namen razviti svojo verzijo.
Dandanes je CPU (logično) posebej in GPU (logično) posebej, čeprav sta fizično na isti rezini. Latency je v tem primeru s stališča GPU-ja še vedno precej boljši, kot na običajnih grafičnih karticah.
Ampak glede na naravo GPUja, zakaj bi se moral posebej sekirat za ta latency ? Kernel itak ne narediš za operacijo nad parimi bytei ampak velikim poljem.
Sicer pa se naredi translacija recimo iz SSE/AVX v to kar GPU-jevi ALU-ji zastopijo. To ni tak problem, večji problem bo spravljat podatke iz enega konca čipa na drugega.
Tisto, kar niso pojasnili, je kako mislijo to ožičit. GPU je vajen mletja podatkov v polju computing enot. Kako boš sedaj kar eni enoti ukazal delat nekaj drugega ( izven polja) samo za ta SSE ukaz ? Večji smisel bi imelo izvajat nekakšne mikrokernele, kjar bi namesto zaporedja SSE ukazov pač napisal programček za GPU in ga poslal v delo. Fajn. Ampak zakaj je to tak problem z diskretno kartico ?
Recimo že compute je na današnjih GPU-jih povsem ločen način obratovanja GPU-ja. Lahko imaš grafiko (pixel/vertex/geometry/domain/hull shaderje) ali pa compute shaderje. Oboje sočasno ne gre.
Zakaj ne ? A ne gre samo za izvajanje drugega programa ?
ČISTI kretenizem IMHO. Za tole bi morali tistega CEO-ta ustrelit. Dobesedno. Domneval sem, da so to naredili namerno, ker že imajo ali pa imajo namen razviti svojo verzijo.
Saj je odletel... Sam ne vem pod čigavo taktirko se je to zgodilo Hector Ruiz-ovo ali Dirk Mayer-jevo.
Ampak glede na naravo GPUja, zakaj bi se moral posebej sekirat za ta latency ? Kernel itak ne narediš za operacijo nad parimi bytei ampak velikim poljem.
S stališča tradicionalnih GPU taskov je nižji latency seveda brez veze. Vprašanje edino če se kdo spomni kaj netradicionalnega gor počet.
Tisto, kar niso pojasnili, je kako mislijo to ožičit. GPU je vajen mletja podatkov v polju computing enot. Kako boš sedaj kar eni enoti ukazal delat nekaj drugega ( izven polja) samo za ta SSE ukaz ? Večji smisel bi imelo izvajat nekakšne mikrokernele, kjar bi namesto zaporedja SSE ukazov pač napisal programček za GPU in ga poslal v delo. Fajn. Ampak zakaj je to tak problem z diskretno kartico ?
To je tisto ja... Mikrokernel bi moral bit večji za diskretno kartico, da se skrije latenca čez PCI-Ex. Kolikor sem jaz zastopil mislijo dejansko reuse-at ALU-je?
Zakaj ne ? A ne gre samo za izvajanje drugega programa ?
Bi si mislil, ampak ne. Dejansko ima compute precej več omejitev (recimo thread grupe), ki niso prisotne v grafičnem načinu. Scheduling se dela čisto drugače. Compute je en task, oziroma paket neodvisnih taskov. V grafičnem načinu en task (vertex shader) fila drug task (pixel shader) z inputom, ki v principu ne zapusti čipa. Eden večji feature-jev za Fermi je to, da lahko izvaja več povsem različnih kernelov sočasno... Za grafičen svet je to veljalo že od nekdaj. AMD je tukaj še mal bolj očutljiv. Radeon-i imajo za OpenCL največ 256 threadov v grupi (Fermi 1024). Tako da, če lahko preživiš z omejitvemi pixel shaderjev (in se ti da s tem ukvarjat ), bo ista koda v pixel shaderjih lahko hitrejša kot v compute shaderjih.
Saj je odletel... Sam ne vem pod čigavo taktirko se je to zgodilo Hector Ruiz-ovo ali Dirk Mayer-jevo.
Eh, to da so ga spustili z nagrado $20M zame ni enako temu, da bi odletela čez havbo avta pod pritiskom šiber v drive-by shootingu, kar si je vsaj prvi več kot zaslužil- za drugega ne vem.
senitel a ti se kaj delas na razvoju grafik al spremljas samo ljubiteljsko?
kaj je bilo pa tisto, ko je brane2 govoril, da so veliko inzenirjev odpustili, ce sem prav razumel? (zakaj?)
Ljubiteljsko, sem pa še zmer v kontaktu. Odpuščal? Kdo, AMD?
Brane2: Tole je precej dobra zadeva. Tudi komentarje se splača prebrat vsaj en NV arhitekt (Ignacio Castano) se je oglasil. Še vedno pa manjka kar nekaj detajlov.
Ok...intel baje ze intenzivno dela na manjsi porabi.A AMD temu kaj sledi?...sej ne da bi me rabl skrbet vsaj z veleumi iz Slovenije, ki mecejo miljarde v razne TES bloke ampak cist tko informativno...mogoce bi si kdaj radi omislili pisarno, kjer celo rabis radiatorje, ko imas masine prizgane :)
Intel bo spet klical Izrael, nej jim pomaga. Nakar bodo ti čez dve leti dobavil re-re-re-re-respinan penitum-pro na 10nm, ki bo pometel s konkurenco.
V resnici si želim, da bi dobili tretjega igralca (magari RISC), samo to se ne bo zgodilo. Ne pozabit kako denaren je Intel. In kolk pametne ljudi ima v Izraelu ;).
a cortex a-15 (in prejsnji) niso multithreaded? to pomeni, da gor lavfa lahko samo ena aplikacija naenkrat, kot v starem dosu al kako? al naj bi bilo tole http://slo-tech.com/novice/t434662 bolj podobno hyperthreadingu?
>Par "fat coreov" predvsem za CPU computing, več deset lean coreov za pomožne zadeve in večsto >ultralean coreov kot shaderji recimo.
Ko je izšel PS3 sem bil jaz navdušen nad Cell arhitekturo. V tistem času sem delal projekte v VS 2005, zato se nisem spuščal v podrobnosti, ampak sem upal, da bodo naslednje generacije Cell arhitekture imele en močan PPU (recimo 2/4/8 threadov), potem osnovane na PowerPC ene 4/8/16 šibke enote (ki bi vsaka *lahko* tudi furala več threadov, če bi se splačalo), in polja SPEjev v malo drugačni, optimizirani in redesignani obliki. Tako bi IBM+Sony+Toshiba postali tretji igralec na trgu. In če bi pametno naredili arhitekturo, bi lahko "po naročilu si sam sestavil" koliko česa bi bilo v procesorju in s tem tudi moč in porabo. Kar mi ni jasno je edino to, koliko bi lahko iz take arhitekture lahko potegnil računanje grafike - v smislu za igranje iger. Bi "močna" konfiguracija v enem čipu lahko konkurirala novodobnim GPUjem? (To si nisem na jasnem, ker je Intelov Larrabee sprva bil najavljen kot GPU potem so pa naslednika Intel MIC najavili kot koprocesor za hpc)
Glede Cella: doživel je potem še enega (ali dva) naslednika, se znašel v Sony in drugih televizijah, potem so ga pa ukinili.
--
>ceprav ne vem, ce je decode za x86 - > radeon vliw sploh mozen... brane, jst?
Ne in ja. V x86 arhitekturi je več stvari (se mi res ne da naštevati), ampak načeloma bi nekaj delov res lahko pohitril, ker sploh ne bi rabil (de)koderja, kjer bi se pa moral zaje***ati s tem (da bi imel (de)koder), pa bi bilo bolje, da bi CPUja enote pustil pri miru. To sem upal, da je pogruntal AMD s Fusion, pa žal ni. Sam tudi ne vem, kako bi pri CPU+GPU v enem čipu (več ENAKIH pipelineov) deloval L1i, kako bi scheduler vedel katero "GPU" ali "CPU" dato filati enotam za izračunavanje, da bi bil izkoristek pozitiven.
Čeprav moram pa priznati, da se na grafično arhitekturo spoznam samo površinsko/poljudno. Nisem nikoli razmišljal, kako bi obšel slabosti sodobnih GPUjev, ki so jih že opisali zgoraj. (Tudi ARM za telefone ima ločen CPU in GPU, pa čeprav zlepljena skupaj.)
Long story short: pojma nimam... :) (de)koder bi bil možen, ampak ali bi bil smiseln?
Islam is not about "I'm right, you're wrong," but "I'm right, you're dead!"
-Wole Soyinka, Literature Nobelist
|-|-|-|-|Proton decay is a tax on existence.|-|-|-|-|
>>Par "fat coreov" predvsem za CPU computing, več deset lean coreov za pomožne zadeve in večsto >>ultralean coreov kot shaderji recimo.
>V tistem času sem delal projekte v VS 2005, zato se nisem spuščal v podrobnosti, ampak sem upal, da >bodo naslednje generacije Cell arhitekture imele en močan PPU (recimo 2/4/8 threadov), potem >osnovane na PowerPC ene 4/8/16 šibke enote (ki bi vsaka *lahko* tudi furala več threadov, če bi se >splačalo), in polja SPEjev v malo drugačni, optimizirani in redesignani obliki.
Zamešal sem timeline. Po izidu PS3 o Cellu kot o CPU+GPU sploh nisem razmišljal. Sem pa spremljal developerje, tudi nekaj kolegov, in kakšen pain je programiranje zanj. Spremljal sem tudi kaj se z njim dogaja, zato vem, da je več verzij.
Kar sem zgoraj opisal je kraja Branetove ideje zmiskana z razmišljanjem, kako bi združil CPU in GPU v učinkovito enoto. Skalabilno od 1W porabe do 100W porabe.
Zakaj sem na takšen način pisal? Sploh ne, da bi izpadel pameten in da sem o tej temi razmišljal leta nazaj, ampak zato, ker sem post pisal po odlomkih in pred pritiskom gumba Pošlji, nisem prebral kaj sem vse napisal. Moj pes ima drisko in ko me prosi ven, treba laufati. :/ Zato sem tudi na minimalcu spanja...
Brane, se ti opravičujem.
Islam is not about "I'm right, you're wrong," but "I'm right, you're dead!"
-Wole Soyinka, Literature Nobelist
|-|-|-|-|Proton decay is a tax on existence.|-|-|-|-|