vir: Microsoft
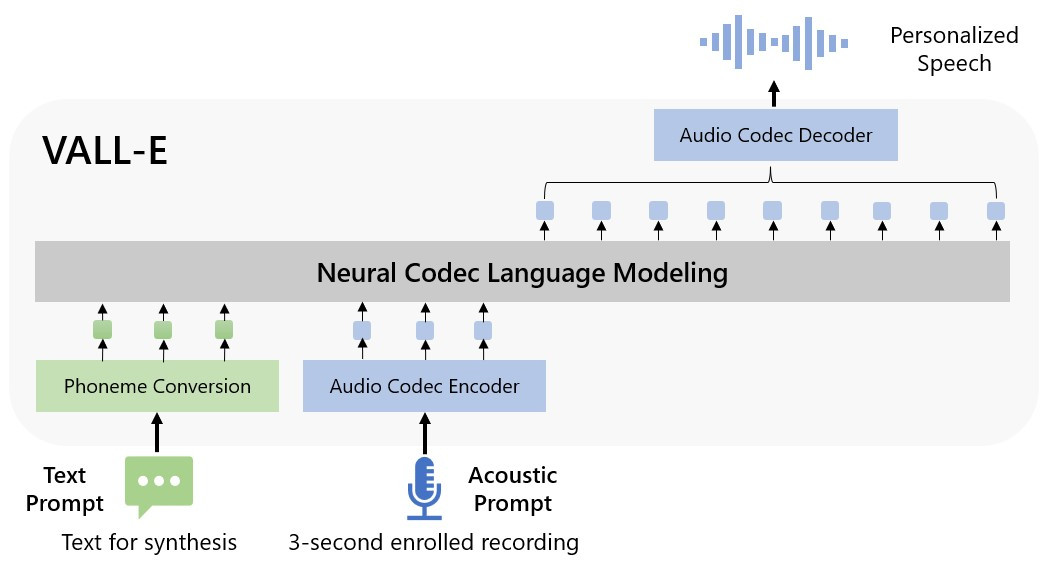
Ob aktualni poplavi generativnih algoritmov vizualnih vsebin, ki zmorejo ustvarjati slike, video posnetke in 3D modele, nezadržno napreduje tudi generiranje zvoka, oziroma človeškega govora. Pri Microsoftu so pred tednom dni predstavili takšen algoritem VALL-E, ki zmore pisani tekst pripovedovati z zvenom in emocionalnim patosom osebe, ki mu je predala že zgolj 3-sekundni vzorec svojega govora. Seveda izdelki, ki jih je mogoče slišati na predstavitveni strani, niso brezhibni in ponekod še vedno izpadejo precej robotski, toda kot prototip nove tehnologije algoritem vseeno navduši. Zaradi potenciala za ponarejanje identitete, oziroma zlorabe, ga Microsoft zaenkrat še ne bo spustil iz laboratorijev, podjetje pa je ravno pred dnevi vnovič podrobneje razdelalo svojo strategijo odgovorne rabe strojne inteligence.
VALL-E je sicer zasnovan na tehnologiji EnCodec, ki so jo lansko jesen predstavili v Meti in je v osnovi sicer namenjena naprednemu stiskanju zvoka, z desetkrat višjo stopnjo kompresije od standarda MP3. Tako se izziva oponašanja govora loti iz samosvoje smeri; medtem ko običajni pristopi iz teksta generiran govor nakdnadno prilagajajo določeni osebi s spreminjanjem tonov in zvena, pa VALL-E štarta iz informacij, "zapakiranih" v skompresirane žetone EnCodeca. Kakor Microsoftovi inženirji razložijo v strokovnem članku, so model trenirali na Metini knjižnici LibriLight, ki vsebuje za 60.000 ur angleškega govora nekaj čez 7000 oseb. Rezultat algoritma je najboljši, če oseba govori podobno kot kateri izmed govorcev v tej bazi podatkov.
